
1 Introduction
Genome editing, including the use of CRISPR-Cas9 (CRISPR) technology, has the potential to contribute significant improvements to agriculture and food security [Huang et al., 2016 ; Huesing et al., 2016 ; Ishii and Araki, 2016 ; Wolter and Puchta, 2017 ]. Public attitudes can shape the direction in which science advances, and recent history with another biotechnology — genetically modified organisms (GMOs) — shows that negative public attitudes toward emergent scientific issues can lead to rejection of a particular technology [McFadden, 2017 ; Nielsen, 2003 ]. The lay public has been shown to perceive significantly more risk from biotechnology applications than experts [Savadori et al., 2004 ]. Thus, lack of public acceptance may be a barrier to the potential agricultural applications of CRISPR and genome editing technologies. While there is data indicating public support for human applications of genome editing for disease prevention and treatment [Gaskell et al., 2017 ; Scheufele et al., 2017 ], further research is necessary to understand stakeholder group’s perceptions of CRISPR’s agricultural applications.
Four key publics may play an important role in the adoption of CRISPR into the food and agricultural system. Scientists, as the holders of expert knowledge, play a critical role in communicating science to society [Burns, O’Connor and Stocklmayer, 2003 ]. Farmers are a central link the agricultural products value chain, and decide whether to adopt biotechnologies and cultivate gene-edited plants [Hillyer, 1999 ]. Agricultural policy professionals are part of the institutional structure that will determine how the technology can be used [Belson, 2000 ]. And members of the general public make individual decisions about consumption of biotech foods and may give political support to permissive policies. Despite the potential widespread applications of the technology and the importance of these sectors, little is known about how these various agricultural-domain stakeholders conceive of genome editing.
The current study aims to fill this gap in our understanding, and ultimately facilitate the engagement of these publics with discussions about genome editing and its application to agriculture [Nisbet, 2018 ; Scheufele et al., 2017 ]. We investigate the knowledge and perceptions of CRISPR held by four different key audiences that each play a different role in the adoption of the technology. Through the use of semantic network analysis and natural language processing of short essay responses, we examine and compare the mental representations of CRISPR between the different groups.
1.1 Perceptions of risks and benefits
Acceptance of new technologies is related to the perceptions of risks and benefits associated with those technologies [Flynn, 2007 ; Frewer et al., 2011 ; Rogers, 2010 ; Vishwanath and Barnett, 2011 ]. Perceptions of risk held by the public are not based solely on objective data and scientific understanding of an issue, but also incorporate subjective and value-laden aspects [Slovic, 2016 ]. Both physically objective and socially constructed risks can result in policy conflict [Douglas and Wildavsky, 1982 ]. As the gap between scientific, objective assessment of risk and the more subjective view of the public widens, so does the magnitude of possible conflict over policy action.
Trust in information sources has frequently been identified as an essential variable for understanding people’s risk perceptions [Wynne, 1980 ; Flynn, 2007 ; Lobb, 2005 ; Slovic, 1999 ]. Studies on the acceptance of the application of biotechnology to agricultural crops show trust in science and/or those regulating the technology to be important variables [Allum, 2007 ; Rodríguez-Entrena and Salazar-Ordóñez, 2013 ; Siegrist, 2000 ]. For example, Allum [ 2007 ] found that multiple dimensions of trust in genetic scientists, including perceived shared values, drive perceptions of risk associated with GM foods.
While CRISPR is in the early stages of introduction to society, genetically modified (GM) foods provide an apt comparison from which to draw lessons. Negative attitudes toward GM foods are associated with insufficient knowledge of the technology, lack of trust in developers or regulatory effectiveness, poor risk-benefit communication, and ethical implications [Lucht, 2015 ; Siegrist, 1999 ; Siegrist, Connor and Keller, 2012 ; Tanaka, 2004 ; Wunderlich and Gatto, 2015 ]. Shew et al. [ 2018 ] found that familiarity with biotechnology and perceptions of its safety were the primary determinants of individuals’ stated willingness to consume both CRISPR and GM foods, and that across multiple countries people are more willing to consume CRISPR than GM foods. Members of the public find GM foods more acceptable when the perceived personal and societal benefits (health, economic, social, environmental) outweigh the perceived risks [De Steur et al., 2010 ; Frewer, Scholderer and Bredahl, 2003 ], when perceived scientific uncertainty is lower [Frewer, 2003 ; Lusk et al., 2004 ], and when perceived naturalness is higher [Sjöberg, 2008 ]. To avoid conflation between GM foods and CRISPR-edits foods and to recognize genome editing as a potential tool [Doxzen and Henderson, 2020 ], it is important to examine the representations of different groups’ perceptions surrounding CRISPR.
1.2 Social representations theory
The combined corpora of survey content can be analyzed through the lens of social representations theory (SRT) [Moscovici, 2000 ]. SRT is an epistemological theory concerned with how individuals, groups and communities collectively make sense of societally relevant issues [Marková, 2008 ]. Social representations are constellations of attitudes and perceptions [Doise, Clémence and Lorenzi-Cioldi, 1994 ], that play an integral role in the development of common sense knowledge as well as “the elaborating of a social object by the community for the purpose of behaving and communicating” [Moscovici, 1963 , p. 251].
A central premise of SRT is that the representations held by lay publics are not by default not viewed as incorrect or mistaken relative to the scientific viewpoint. Instead, lay representations reveal how “objects are understood in the public domain” [Bauer and Gaskell, 2008 , p. 338; Callaghan, Moloney and Blair, 2012 ]. Moloney et al. [ 2014 ] contend that the elicitation of representations across groups can provide a foundation for societal engagement of issues, in their case climate change, by providing an arena for dispute.
SRT has been employed extensively in the service of understanding environmental concern [Castro, 2006 ], including studies on public understandings of techno-scientific innovation in the domains of hydrogen energy [Sherry-Brennan, Devine-Wright and Devine-Wright, 2010 ], fracking [Bigl, 2020 ], water recycling [Callaghan, Moloney and Blair, 2012 ] and biotechnology [Bauer and Gaskell, 2008 ; Castro, 2006 ].
Following the SRT perspective, the groups in this study are culturally different and the individuals in them have been socialized differently as a part of that group membership. Additionally, various publics will interact in different ways and at varying levels of intensity with CRISPR and its products. Scientists working on genetics engage with CRISPR as a concept more frequently than do government employees, farmers and most of the general public. The technology presents the possibility of different challenges and opportunities for each group. Thus, we expect the different stakeholder groups to display different representations of CRISPR.
SRT and text analysis of survey response data allows us to ask questions about the way key publics — scientists, policymakers, farmers, and the general public — view an emerging agricultural biotechnology. Thus, we propose the following research questions:
- How do the semantic networks reveal different perceptions related to the acceptance of CRISPR across the four stakeholder groups?
- Specifically, does the lay public differ from the experts in their aggregate social representations?
2 Methods
2.1 Recruitment and procedures
In the fall of 2019, we fielded a survey targeting four key groups associated with the adoption of the CRISPR genome editing technology: 1) genetics and genomics faculty at major U.S. land grant universities, 2) staff at federal- and state-level agricultural policymaking institutions, 3) farmers, and 4) the general public. The general public and farmers samples were recruited by Qualtrics, Inc., an online survey platform that allows researchers to build and distribute surveys to representative samples of the general public or specific demographic groups.
Using an online search, we assembled a sampling frame of tenure-track professors in genetics or genomics from the 13 land-grant institutions of the 11 states producing the greatest dollar value from agriculture: California, Iowa, Texas, Nebraska, Minnesota, Illinois, Kansas, North Carolina, Wisconsin, Washington, and Indiana. We included the 817 professors either affiliated with their university’s genetics or genomics department or indicating a focus on these topics on their faculty biography page. We sent each of these scientists an email requesting their participation in a survey about genome editing technologies. Of these 817, 168 filled out the survey, for a response rate of 20.6%.
We recruited policymakers via an email request. Federal congressional staff, as well as California Department of Food and Agriculture (CDFA) personnel, were recruited for the survey. We purchased a contact list of congressional staffers focusing on either the “science and technology” or “agriculture and food” issues from a third-party research organization (Legistorm, www.legistorm.com). The CDFA members were recruited by email, with the department commissioner’s endorsement. The samples from the congressional staff and the CDFA were combined into the policymaker sample, since they did not statistically differ in knowledge, attitudes, or any demographic variable aside from age. A total of 1,114 policy staff were contacted with 83 responding, yielding a response rate of 7.5%. The survey was distributed using the Qualtrics, Inc. software (Provo, UT, version 12) platform.
2.2 Survey
As part of a larger survey that included items to determine the subjects’ knowledge and attitudes towards science and in specific, genome editing and biotechnology, this study examined open-ended responses regarding gene editing. Participants were given definitions of the terms “genome editing” and “genome” (see appendix B for prompt) and asked to compose a short essay (100+ words) on their thoughts and opinions on genome editing and CRISPR. These essay responses were preprocessed to create a corpus for each of the four groups. We used semantic network analysis and topic modeling to investigate semantic meaning at the group level. A third method, keyness analysis, was used to directly compare groups in a pairwise fashion based on the differences in occurrence of specific words.
2.3 Semantic network analysis
We employed semantic network analysis, a content analysis method that uses word frequency and co-occurrence to reveal meaning embedded in text [Danowski, 1993 ; Doerfel, 1998 ]. The theoretical grounding for semantic network analysis originates in the cognitive science literature on the structure of human semantic memory [Collins and Quillian, 1972 ]. The foundational applications within communication occurred in the 1980s and 90s [Carley and Kaufer, 1993 ; Danowski, 1982 ; Doerfel, 1998 ; Jang and Barnett, 1994 ] and researchers continue to use this methodology in the era of big data [Calabrese, Anderton and Barnett, 2019 ; Veltri and Atanasova, 2017 ; Zywica and Danowski, 2008 ]. Social representations can be instantiated as semantic networks at the aggregate level to facilitate the comparison of representations across groups [Veltri, 2013 ].
Four semantic matrices were generated using the survey responses based on word co-occurrence, one for each participant group. The basic network data set is an matrix S , where equals the number of nodes (words) in the analysis and is a measured relationship between nodes and . The measurement of word co-occurrence is the standard for creating links between words in a semantic network. We followed the convention of using a 3-word window for defining links between concepts [see Danowski, 1993 ]; therefore, links were created for words that occurred within three words of one another within each survey response. The frequencies of word co-occurrence were then calculated and ranked. The semantic networks were created using R version 4.0.1 [R Core Team, 2020 ] and the igraph package [Csárdi and Nepusz, 2006 ].
Words with a frequency above the mean (scientists, , policymakers, , farmers, , general public, ), were included in a network visualization (Figure 1 ). After importing the data, the network visualization was adjusted using the ForceAtlas2 layout [Jacomy et al., 2014 ] to examine the spatialization between words. The size of the word label indicated how frequently the word occurred. The presence of an edge represents a connection between two nodes and the width of an edge represents the strength of the association (number of co-occurrences). The more closely related the words were, the shorter the link distance. The visualizations were produced using the Gephi software [Jacomy et al., 2014 ].
We used Louvain community detection to identify cohesive themes within each corpus [Blondel et al., 2008 ]. Community detection is a graph partitioning method which decomposes a network into an arrangement of multiple subgraphs and seeks to maximize modularity, or the fraction of the links that fall within a given group [Newman, 2004 ]. Each subgraph was assigned a unique, arbitrary color for visual examination.
2.4 Topic modeling
Latent Dirichlet Allocation (LDA) topic modeling was also employed to extract summary meaning from the collection of open-ended responses for each stakeholder group. LDA is a three-level hierarchical Bayesian model where each document in the corpus is modelled as a mixture over a set of corpus-wide topics [Blei, Ng and Jordan, 2003 ]. Each topic, in turn, is a distribution over a fixed set of all the words in the corpus, also known as the vocabulary. LDA assumes that the words in a document’s contents are generated by a set of latent topics and attempts to infer those topics that are most likely to have generated the documents. A key assumption in LDA is that the order of words does not matter (bag-of-words) [Blei, Ng and Jordan, 2003 ].
For finding these topics, LDA uses the word co-occurrence pattern in the corpus, such that the more often two words co-occur in a document, the more likely they are to be assigned to the same topic [Aggarwal and Zhai, 2012 ]. An important task for topic modeling is to determine the prior value for ; if is too small, the topics will be overly broad, while if it is too large, the topics may be too overlapping or similar to each other. We determined for each topic model quantitatively by running a series of models , with for each stakeholder corpus, calculating the coherence score for each , and selecting the corresponding to the model with the highest coherence score (see appendix A ). Topic coherence is a measure of a topic’s semantic interpretability and association with well-defined semantic concepts [Newman et al., 2010 ].
2.5 Text keyness
We used a series of pairwise keyness analyses to compare language differences across groups. Keyness is a weighted measure of word frequencies within a particular text corpus, relative to some reference corpus [Bondi and Scott, 2010 ], and can be calculated with a chi-square test. Words keyness scores of the highest absolute value are used disproportionately between groups, indicating the potential for interesting conceptual or terminological differences present that might warrant further investigation [Seale et al., 2010 ].
3 Results
3.1 Semantic network analysis
Figure 1 presents the semantic networks for each group. The various communities or themes are represented by different colors/shades. The size of the word indicates word frequency. A line represents a connection between two words. Its width signifies number of co-occurrences. The more closely related the words are, the shorter the link. For example, for the general public, DNA is the most frequent word and it is strongly related to scientist . Technology , cut , paste , tool , develop and problem make up a theme. Problem is weakly related to the other terms in this theme.
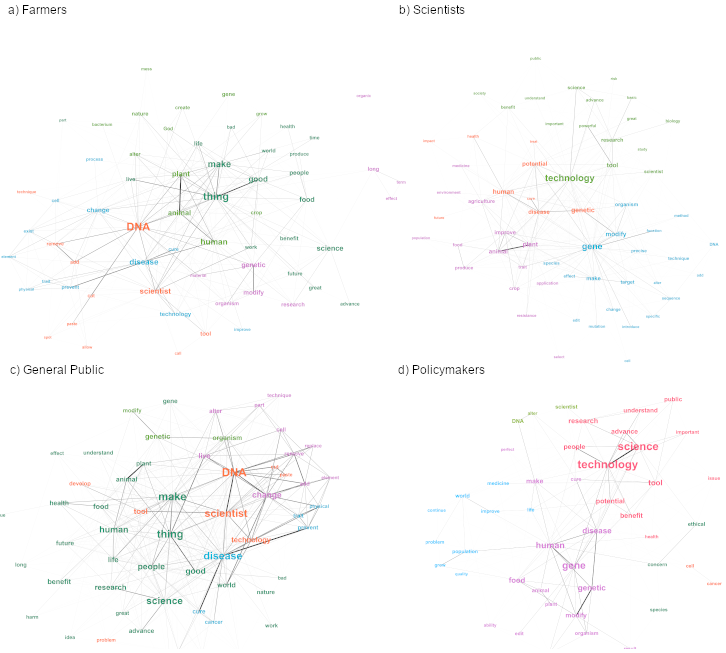
For scientists (Figure 1 a, Table 1 ), the first community contains words referring to the potential societal health benefits ( cure , treat , human , disease ) at some point in the future ( potential , future ). The second community involves a description of the method : it alter s ( modify , change , add , edit , introduce ) in a controlled ( target , precise ) way but acknowledges the possibility of error ( unintended , consequence , mutation ). The third semantic community articulates a wide range of uses and societal benefits ( agriculture , application , plant , animal , crop , food , medicine , resistance ), in the form of ( improve , produce , manipulate , develop ) through the process of select ing a trait . The final community frames the techno-scientific innovation ( science , research , study , biology ) as a potent ( powerful , important , great ) method which can yield societal benefit ( benefit , advance , understand ) but also acknowledges societal risk . The themes that emerged from the scientists’ semantic network are summarized in Table 2 .

As for policymakers (Figure 1 b, Table 1 ), in the first community respondents discussed the general technical process of a scientist alter ing DNA , expressing enthusiasm ( exciting , great ) and application to agriculture , but also acknowledging concerns over public perception ( controversial ). The next community refers to the ethical concern of feed ing the species , composed entirely of words not appearing in the prompt for the essay. The third cluster (purple) consists of perceived societal health benefits ( curing , treating , disease , food ) as well as a general notion that the genomic editing process is to create or modify . The fourth community consists entirely of new terms, invoking the ethical imperative of improving life for a world population that is continuing to grow (positive terms medicine , improve , but also problem ). The fifth community consists mostly of new terms, indicating that CRISPR is an important tool or technology and has the potential to advance understanding and provide health benefits. The final community is somewhat unclear, consisting of give , cancer , cell , and instruction . The themes that emerged from the policymakers’ semantic network are presented in Table 1 .
For farmers (Figure 1 c, Table 1 ), the first semantic community consists entirely of words from the essay’s prompt (see appendix B ) definition of genomic editing (DEF 3). There were no new words provided by the respondents. The second community sees the respondents’ positive reflections on a concept given in the prompt. A large portion of this community is composed of words from the prompt defining genomic editing — altering the genome to change physical form and prevent disease and the desired effects of using it (DEF 1), but with added references to positive societal benefits ( cure , improve ), personalizing ( feel ), and potential conflation with GM ( GMO ). The third community consists of terms in the instruction manual analogy portion ( plants , animals , bacteria ) of the prompt (DEF 2) combined with perceived naturalness ( god , human , nature , important ). Additionally, there is reference to perceived personal economic benefits for the farmers ( grow , crop s). The fourth community refers to research and development around modifications that have a certain effect. The final community is a large one involving judgement ( advance , good , great , benefit and bad ) as well as people and the things they do ( live , produce , work ) in the world . In this community, farmers appear to be grappling with perceived societal benefits vs. risks, but mostly focusing on the benefits.
For the general public (Figure 1 d, Table 1 ), the first community is largely composed of terms from DEF 1, with an expression of uncertainty ( hope ) and benefit ( improve ), as well as an invocation of faith or naturalness ( god ). The second community involves more words from DEF 1, with added terms related to potential societal health benefits : cure and cancer . The third community consists only of words from DEF 3 . In the fourth community respondents added words beyond the prompt and introduce a notion of uncertainty : adding potential and negative to a few generic terms. The fifth community is a large group composed primarily of new words, dealing broadly with society ( human , people , world , life , food , health , nature ) moving in a positive direction ( good , advance , future , benefit ), but also acknowledging the potential risks in general ( bad , harm ).
4 Topic modeling
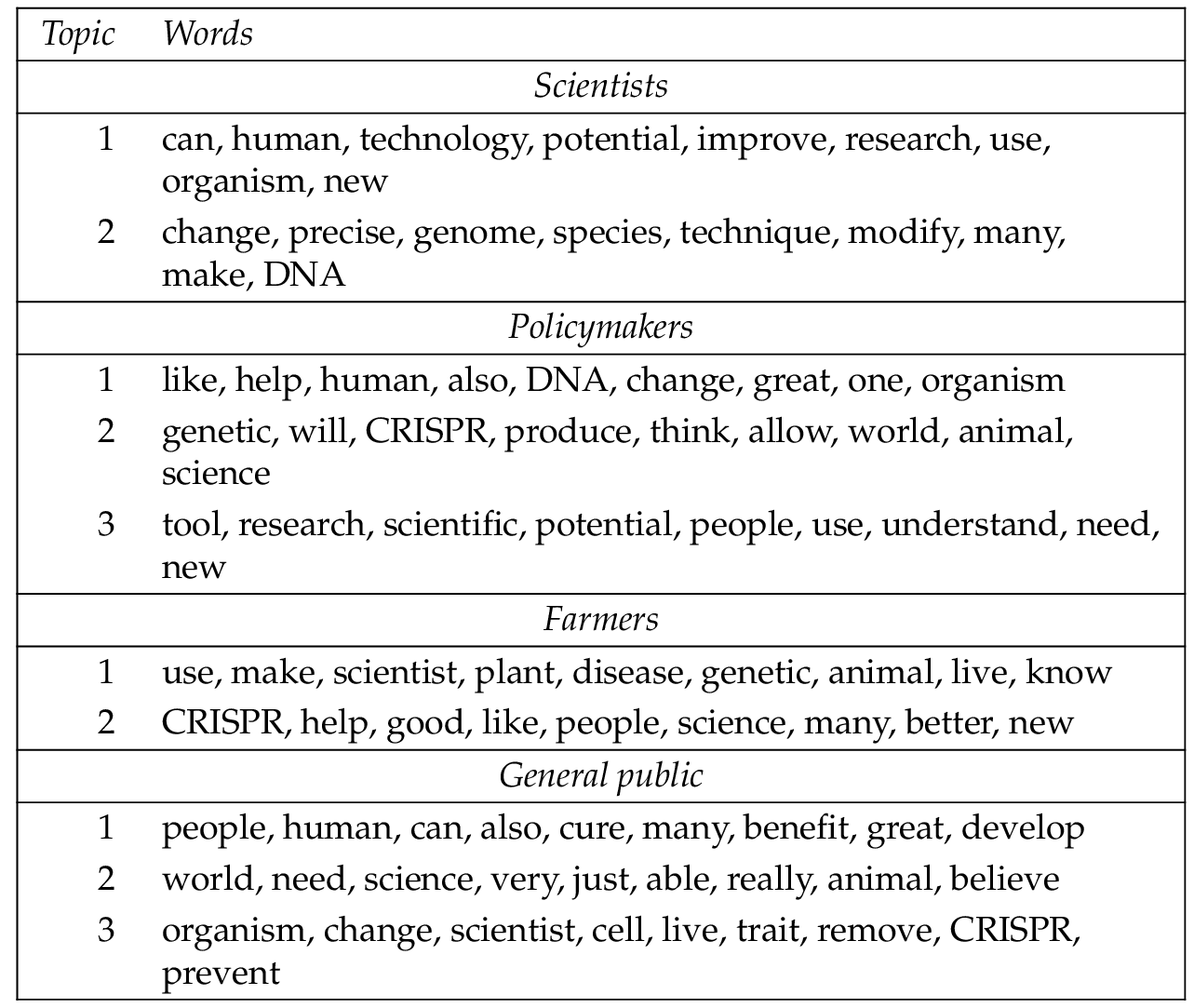
Overall, the topic modeling results confirmed insights provided by the semantic network analysis. Table 1 shows the results from the topic modeling analysis (see appendix A for coherence plots). The analysis of the scientists’ corpus yielded two topics. The first topic contains terms describing the possibility of benefits ( new , potential , improve ) of the technology in general ( human , gene ). The second topic relates more specifically to the process ( technique , precise ) by which GE operates ( change , modify , DNA ).
The model yielded three topics from the policymakers corpus. The first topic contains terms related to societal benefits ( help , great , human ), and the technology in general ( DNA , change ). In the second topic we see the notion of societal benefits provided by the application of CRISPR to agriculture ( allow , food , produce , world ). The third topic echoes the language from scientist Topic 1, discussing the potential of a new scientific method ( tool , technology ) and knowledge ( understand , research ).
The first farmers topic is comprised mostly of prompt words . The second topic relates generally to perceived societal benefits ( human , people , help , good , better ).
The general public Topic 1 relates to the perceived societal benefit s ( human , people , cure , great ). The second topic is difficult to interpret, although it is perhaps related to the need for science in general. Topic 3 contains scientific terms from DEF 1 in the prompt.
4.1 Text keyness
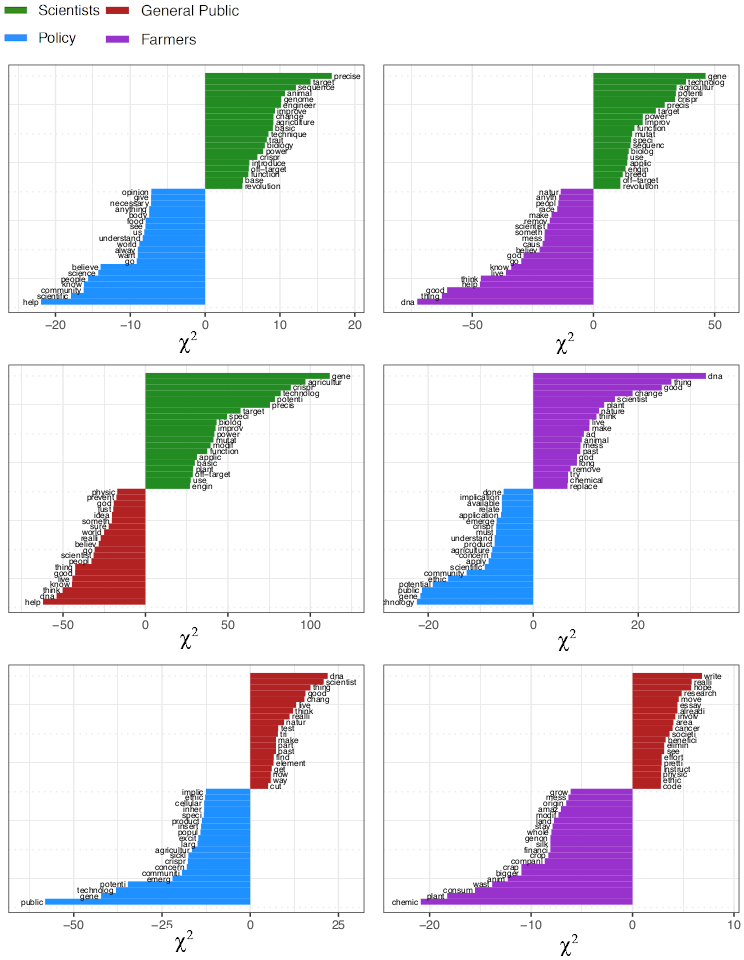
Figure 2 shows the results of the text keyness analysis that compares each pairing of the four stakeholder groups. The terms with the largest negative and positive scores on the signed chi-squared measure of association have the greatest disparity in frequency between the pair of groups. All reported chi-squared values are significant at the level or less.
4.2 Scientists vs. policymakers
While the policymakers group exhibited more technical sophistication than farmers and the general public, the scientists had even more of a technical focus ( technique , precise , target , sequence , introduce , off-target ) and discussed more the active process of using CRISPR ( change , engineer , improve , use , manipulate ). Policymakers, on the other hand, focused on general positive change , with the top term being help . They also spoke more of broadly of societal issues ( people , communities , world , science , food) .
4.3 Scientists vs. farmers
Relative to farmers, the scientists’ corpus focused on CRISPR as a technology , representing a powerful and precise method allowing scientists to target genes , and emphasized that applications and benefits are not certain but rather potential . Farmers, on the other hand, displayed little specificity in their language relative to scientists, with the most unique words being DNA and good . The farmers top unique words contained a reference to faith , with God and believe having high keyness scores.
4.4 Scientists vs. general public
Scientists displayed a high level of technical specificity around the technology , emphasizing its precision precise , target , power , and its potential , but also acknowledged risks around off-target mutations . Scientists also acknowledged the applications to agriculture ( plant , crop ) while the general public did not. The general public had a lower overall keyness score, indicating less unique use of language as well as more generic language ( help , good ). The general public did talk more about the individuals involved in the matter , referencing people and scientists as well as general thoughts about humanity: live , world . Similar to the farmers, the general public referenced faith with God while the scientists did not.
4.5 Policymakers vs. farmers
Relative to policymakers, farmers had a less technical understanding of the issue and relied more heavily on the concepts given in the prompt. They were more likely to judge possible outcomes of the technology ( good , mess ) and indicated an appeal to naturalness ( natural , God ). The appearance of chemical in the list perhaps suggests the potential benefit to farmers of reduced crop inputs. Policymakers focused more on potential societal benefits ( medicine , agriculture , community , public of the emerging technology , while acknowledging ethical concerns .
4.6 Policymakers vs. general public
The term with the highest keyness score for the policymaker group relative to the general public was public , reflecting a focus on the societal implications of CRISPR . Similarly, communities also had a high keyness score. Similar to the scientists, the policymakers group exhibited more technical sophistication in their language use than did the general public, evidenced by very high keyness on potential , gene and technology . The policymakers group also discussed applications of CRISPR to both food systems and medicine , evidenced by the presence of agriculture and sickle , and acknowledged ethical concerns . The words used uniquely by the general public were more limited and seem to represent actions taken by a scientist ( change , test , make , find and cut ).
4.7 Farmers vs. general public
Farmers’ key terms were largely related to agriculture and seem to be primarily concerned with efficient application of chemical inputs on crops : chemical , plant , consume and waste had the highest keyness scores, and the top 20 terms with also included animal , crop , land and farm . Farmers also talked more about the financial implications for CRISPR , mentioning finance and companies . The general public key terms included beneficial , society and cancer , showing a focus on more general perceived societal benefits .
5 Discussion
The current study empirically elucidates perceptions held by four key groups (scientific experts in genetic or genomics, farmers, policymakers and the general public) about gene editing applied to agriculture. Results show convergence across methods and reveal key distinctions in the construction of social representations of this emerging biotechnology based on semantic structure and risks and benefits emphasized across the groups.
Overall, the semantic network, topic modeling, and keyness analyses show that scientists utilize a high level of technical scientific terminology to emphasize the power and precision of the technology. The term “potential” occurs frequently in the scientist corpus, suggesting a somewhat cautious framing of the state of the science. Scientists discussed the potential societal benefits of CRISPR applied to developing medicine and curing disease, modification of plants and animals for agricultural purposes and an enhanced understanding of biology.
Policymakers also exhibited a relatively high level of technical sophistication while emphasizing the perceived societal benefits. While acknowledging the technology’s potential for controversy and ethical concerns, they spoke broadly of potential societal benefits associated with CRISPR emphasizing feeding global populations. With recent controversy around the ethical concerns associated with genome editing [Calabrese et al., 2020 ] it will be increasingly important to engage with policymakers and other publics for later regulation of these technologies.
Farmers used a relatively low level of scientific terminology but had a generally optimistic representation of the technology. They emphasized perceived personal economic benefits, usually in the form of reduced chemical inputs. Farmers additionally expressed some concern around potential risk related to the perceived naturalness of genome editing. Future message strategies may focus on the potential economic benefits of genome editing technologies and the similarities between natural evolution and CRISPR genome editing [Doxzen and Henderson, 2020 ].
The general public relied on terms contained in the essay prompt when formulating their responses, indicating a low level of prior knowledge of genome editing and CRISPR. This group exhibited a low level of understanding of the issue, framing their responses in evaluative terms and generally expressing uncertainty and perhaps and cautious level of optimism. This underdeveloped social representation provides an opportunity to communicate the potential risks and benefits associated with the CRISPR technology.
Both the general public and farmer groups appealed to religious beliefs, touching on the notions of perceived naturalness and morality. Previous research has shown religiosity to be a predictor for attitudes toward gene editing [Scheufele et al., 2017 ] and other scientific topics. For these stakeholder groups, one’s level of religion may play an important role in determining acceptance of these technologies.
Interestingly, both the policy and general public groups referred to the potential beneficial uses of CRISPR in curing cancer and other diseases, reflecting the broader concerns these groups have regarding the applications of this technology. While the focus of this study was on agricultural applications of genome editing, these findings parallel the general approval of this technology for disease prevention and treatment [Scheufele et al., 2017 ].
Overall, this research was conducted to facilitate engagement with various publics about genome editing and its applications to agriculture. Public engagement regarding genome editing has been called for human applications [Scheufele et al., 2017 ; National Academies of Sciences, Engineering, and Medicine, 2017 ]. Such an effort starts with social science research that assesses public discourse about genome editing [Nisbet, 2018 ]. There are extensive purported benefits of the agricultural application of genome editing. Raising awareness of these benefits and the potential risks will be key in moving toward the determination of an appropriate way to integrate this new technology into society. By identifying the similarities and differences among various groups’ perceptions of genome editing, we have uncovered opportunities to promote public dialog about the potential benefits and pitfalls of this technology. This is especially important since the use of genome editing technologies raises significant ethical, social, and legal issues due to their ability to create unanticipated environmental or social effects.
The combination of methodologies employed in this study is unique. Keyness analysis is used by more by linguists than communication researchers. As illustrated here, keyness analysis can effectively complement other text analysis methods such as semantic network analysis and topic modeling by providing a more explicit comparison between groups and corpora. Topic modeling provided convergent evidence with, but little additional insight beyond, the semantic network analysis. The collection of topic terms was nearly a subset of the terms identified by the semantic network analysis (93 out of the 96 topic terms). While topic modeling can reveal similarities between groups other than semantic ones [Leydesdorff and Nerghes, 2017 ], it appears to not have done so in this case.
This research has several limitations. We had unequal sample sizes and response rates across the groups. In particular, the congressional staff response rate was low. This demographic is difficult to access, and future research would benefit from building relationships with congressional offices over time. Our data captures a narrow slice of time within an ongoing evolution of public understanding of a techno-scientific issue. At this early stage of utilization of the technology, farmers and the general public have generally low levels of familiarity with CRISPR; as familiarity increases, perceptions may change. Future research should sample these the stakeholders as their understanding and perception of CRISPR evolves, as well as additional groups as they emerge.
6 Conclusion
This study shows how multiple groups with interests in agricultural CRISPR display differently constructed perceptions of the technology. The general public and farmers, as potential consumers of CRISPR products, exhibited a low level of sophistication but positive orientation toward CRISPR. There is little evidence to suggest any conflation with GMOs to complicate outreach efforts. Non-expert publics did not appear to be knowledgeable of CRISPR and thus, it seems they do not hold firmly formed perceptions about genome editing at this time. Agricultural policy professionals have some baseline understanding of the technology and the associated potential societal benefits and will play an increasing role in the event that CRISPR proceeds towards deployment. Overall, these results suggest an openness to the presentation of new information about the technology and an opportunity for engagement.
Acknowledgments
This research was funded by the University of California’s Innovative Genomics Institute.
A Topic model evaluation
B Prompt for open-ended response essay
“Please read the following description about genome editing and write a short essay (100 words) about your thoughts and opinions on genome editing and CRISPR .
Genome: the term genome encompasses all of an organism’s genetic material, or DNA. It can be thought of as the instruction manual for living things, including plants, bacteria, and animals ( DEF 1 ).
Genome editing: genome editing describes a range of techniques that make it possible to alter a selected part of the genome in a living cell by removing or changing existing elements or adding new ones to changes in physical traits and prevent disease ( DEF 2 ). Scientists use different technologies to do this. These technologies cut and paste the DNA at a specific spot, allowing scientists to remove, add, or replace the DNA ( DEF 3 ).
Recently, a new genome editing tool called CRISPR, has been developed. Many scientists who perform genome editing now use CRISPR.”
References
-
Aggarwal, C. C. and Zhai, C., eds. (2012). Mining text data. Boston, MA, U.S.A.: Springer Science & Business Media. https://doi.org/10.1007/978-1-4614-3223-4 .
-
Allum, N. (2007). ‘An empirical test of competing theories of hazard-related trust: the case of GM food’. Risk Analysis 27 (4), pp. 935–946. https://doi.org/10.1111/j.1539-6924.2007.00933.x .
-
Bauer, M. W. and Gaskell, G. (2008). ‘Social representations theory: a progressive research programme for social psychology’. Journal for the Theory of Social Behaviour 38 (4), pp. 335–353. https://doi.org/10.1111/j.1468-5914.2008.00374.x .
-
Belson, N. A. (2000). ‘US regulation of agricultural biotechnology: an overview’. AgBioForum 3 (4), pp. 268–280. URL: http://hdl.handle.net/10355/378 .
-
Bigl, B. (2020). ‘Stop the frack! Exploring the media’s portrayal of the social representation of an anti-fracking protest at the Baltic Sea’. Environmental Communication 14 (2), pp. 271–286. https://doi.org/10.1080/17524032.2019.1651367 .
-
Blei, D. M., Ng, A. Y. and Jordan, M. I. (2003). ‘Latent Dirichlet allocation’. Journal of Machine Learning Research 3, pp. 993–1022. URL: http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf .
-
Blondel, V. D., Guillaume, J.-L., Lambiotte, R. and Lefebvre, E. (2008). ‘Fast unfolding of communities in large networks’. Journal of Statistical Mechanics: Theory and Experiment 2008 (10), P10008. https://doi.org/10.1088/1742-5468/2008/10/P10008 .
-
Bondi, M. and Scott, M., eds. (2010). Keyness in texts. Amsterdam, The Netherlands and Philadelphia, PA, U.S.A.: John Benjamins Publishing Company. https://doi.org/10.1075/scl.41 .
-
Burns, T. W., O’Connor, D. J. and Stocklmayer, S. M. (2003). ‘Science communication: a contemporary definition’. Public Understanding of Science 12 (2), pp. 183–202. https://doi.org/10.1177/09636625030122004 .
-
Calabrese, C., Anderton, B. N. and Barnett, G. A. (2019). ‘Online representations of “genome editing” uncover opportunities for encouraging engagement: a semantic network analysis’. Science Communication 41 (2), pp. 222–242. https://doi.org/10.1177/1075547018824709 .
-
Calabrese, C., Ding, J., Millam, B. and Barnett, G. A. (2020). ‘The uproar over gene-edited babies: a semantic network analysis of CRISPR on Twitter’. Environmental Communication 14 (7), pp. 954–970. https://doi.org/10.1080/17524032.2019.1699135 .
-
Callaghan, P., Moloney, G. and Blair, D. (2012). ‘Contagion in the representational field of water recycling: informing new environment practice through social representation theory’. Journal of Community & Applied Social Psychology 22 (1), pp. 20–37. https://doi.org/10.1002/casp.1101 .
-
Carley, K. M. and Kaufer, D. S. (1993). ‘Semantic connectivity: an approach for analyzing symbols in semantic networks’. Communication Theory 3 (3), pp. 183–213. https://doi.org/10.1111/j.1468-2885.1993.tb00070.x .
-
Castro, P. (2006). ‘Applying social psychology to the study of environmental concern and environmental worldviews: contributions from the social representations approach’. Journal of Community & Applied Social Psychology 16 (4), pp. 247–266. https://doi.org/10.1002/casp.864 .
-
Collins, A. M. and Quillian, M. R. (1972). ‘Experiments on semantic memory and language comprehension’. In: Cognition in learning and memory. Ed. by L. W. Gregg. New York, NY, U.S.A.: John Wiley & Sons.
-
Csárdi, G. and Nepusz, T. (2006). ‘The igraph software package for complex network research’. InterJournal Complex Systems , 1695. URL: http://igraph.sf.net .
-
Danowski, J. A. (1982). ‘Computer-mediated communication: a network-based content analysis using a CBBS conference’. Annals of the International Communication Association 6 (1), pp. 905–924. https://doi.org/10.1080/23808985.1982.11678528 .
-
— (1993). ‘Network analysis of message content’. In: Progress in communication sciences. Ed. by W. D. Richards and G. A. Barnett. Vol. 12. Norwood, NJ, U.S.A.: Ablex Publishing Corporation, pp. 197–221.
-
De Steur, H., Gellynck, X., Storozhenko, S., Liqun, G., Lambert, W., Van Der Straeten, D. and Viaene, J. (2010). ‘Willingness-to-accept and purchase genetically modified rice with high folate content in Shanxi Province, China’. Appetite 54 (1), pp. 118–125. https://doi.org/10.1016/j.appet.2009.09.017 .
-
Doerfel, M. L. (1998). ‘What constitutes semantic network analysis? A comparison of research and methodologies’. Connections 21 (2), pp. 16–26.
-
Doise, W., Clémence, A. and Lorenzi-Cioldi, F. (1994). ‘Le charme discret des attitudes’. Papers on Social Representations / Textes sur les Représentations Sociales 3 (1), pp. 1–3.
-
Douglas, M. and Wildavsky, A. (1982). Risk and culture: an essay on the selection of technological and environmental dangers. 1st ed. Oakland, CA, U.S.A.: University of California Press. URL: http://www.jstor.org/stable/10.1525/j.ctt7zw3mr .
-
Doxzen, K. and Henderson, H. (2020). ‘Is this safe? Addressing societal concerns about CRISPR-edited foods without reinforcing GMO framing’. Environmental Communication 14 (7), pp. 865–871. https://doi.org/10.1080/17524032.2020.1811451 .
-
Flynn, R. (2007). ‘Risk and the public acceptance of new technologies’. In: Risk and the public acceptance of new technologies. Ed. by R. Flynn and P. Bellaby. London, U.K.: Palgrave Macmillan, pp. 1–23. https://doi.org/10.1057/9780230591288_1 .
-
Frewer, L. J. (2003). ‘Societal issues and public attitudes towards genetically modified foods’. Trends in Food Science & Technology 14 (5–8), pp. 319–332. https://doi.org/10.1016/s0924-2244(03)00064-5 .
-
Frewer, L. J., Bergmann, K., Brennan, M., Lion, R., Meertens, R., Rowe, G., Siegrist, M. and Vereijken, C. (2011). ‘Consumer response to novel agri-food technologies: implications for predicting consumer acceptance of emerging food technologies’. Trends in Food Science & Technology 22 (8), pp. 442–456. https://doi.org/10.1016/j.tifs.2011.05.005 .
-
Frewer, L. J., Scholderer, J. and Bredahl, L. (2003). ‘Communicating about the risks and benefits of genetically modified foods: the mediating role of trust’. Risk Analysis 23 (6), pp. 1117–1133. https://doi.org/10.1111/j.0272-4332.2003.00385.x .
-
Gaskell, G., Bard, I., Allansdottir, A., Vieira da Cunha, R., Eduard, P., Hampel, J., Hildt, E., Hofmaier, C., Kronberger, N., Laursen, S., Meijknecht, A., Nordal, S., Quintanilha, A., Revuelta, G., Saladié, N., Sándor, J., Borlido Santos, J., Seyringer, S., Singh, I., Somsen, H., Toonders, W., Torgersen, H., Torre, V., Varju, M. and Zwart, H. (2017). ‘Public views on gene editing and its uses’. Nature Biotechnology 35 (11), pp. 1021–1023. https://doi.org/10.1038/nbt.3958 .
-
Hillyer, G. (1999). ‘Biotechnology offers U.S. farmers promises and problems’. AgBioForum 2 (2), pp. 99–102. URL: http://hdl.handle.net/10355/1206 .
-
Huang, S., Weigel, D., Beachy, R. N. and Li, J. (2016). ‘A proposed regulatory framework for genome-edited crops’. Nature Genetics 48 (2), pp. 109–111. https://doi.org/10.1038/ng.3484 .
-
Huesing, J. E., Andres, D., Braverman, M. P., Burns, A., Felsot, A. S., Harrigan, G. G., Hellmich, R. L., Reynolds, A., Shelton, A. M., Jansen van Rijssen, W., Morris, E. J. and Eloff, J. N. (2016). ‘Global adoption of genetically modified (GM) crops: challenges for the public sector’. Journal of Agricultural and Food Chemistry 64 (2), pp. 394–402. https://doi.org/10.1021/acs.jafc.5b05116 .
-
Ishii, T. and Araki, M. (2016). ‘Consumer acceptance of food crops developed by genome editing’. Plant Cell Reports 35 (7), pp. 1507–1518. https://doi.org/10.1007/s00299-016-1974-2 .
-
Jacomy, M., Venturini, T., Heymann, S. and Bastian, M. (2014). ‘ForceAtlas2, a continuous graph layout algorithm for handy network visualization designed for the Gephi software’. PLoS ONE 9 (6), e98679. https://doi.org/10.1371/journal.pone.0098679 .
-
Jang, H.-Y. and Barnett, G. A. (1994). ‘Cultural differences in organizational communication: a semantic network analysis 1’. Bulletin of Sociological Methodology / Bulletin de Méthodologie Sociologique 44 (1), pp. 31–59. https://doi.org/10.1177/075910639404400104 .
-
Leydesdorff, L. and Nerghes, A. (2017). ‘Co-word maps and topic modeling: a comparison using small and medium-sized corpora ( )’. Journal of the Association for Information Science and Technology 68 (4), pp. 1024–1035. https://doi.org/10.1002/asi.23740 .
-
Lobb, A. (2005). ‘Consumer trust, risk and food safety: a review’. Acta Agriculturae Scandinavica, Section C — Food Economics 2 (1), pp. 3–12. https://doi.org/10.1080/16507540510033424 .
-
Lucht, J. M. (2015). ‘Public acceptance of plant biotechnology and GM crops’. Viruses 7 (8), pp. 4254–4281. https://doi.org/10.3390/v7082819 .
-
Lusk, J. L., House, L. O., Valli, C., Jaeger, S. R., Moore, M., Morrow, J. L. and Traill, W. B. (2004). ‘Effect of information about benefits of biotechnology on consumer acceptance of genetically modified food: evidence from experimental auctions in the United States, England, and France’. European Review of Agricultural Economics 31 (2), pp. 179–204. https://doi.org/10.1093/erae/31.2.179 .
-
Marková, I. (2008). ‘The epistemological significance of the theory of social representations’. Journal for the Theory of Social Behaviour 38 (4), pp. 461–487. https://doi.org/10.1111/j.1468-5914.2008.00382.x .
-
McFadden, B. R. (2017). ‘The unknowns and possible implications of mandatory labeling’. Trends in Biotechnology 35 (1), pp. 1–3. https://doi.org/10.1016/j.tibtech.2016.09.009 .
-
Moloney, G., Leviston, Z., Lynam, T., Price, J., Stone-Jovicich, S. and Blair, D. (2014). ‘Using social representations theory to make sense of climate change: what scientists and nonscientists in Australia think’. Ecology and Society 19 (3), 19. https://doi.org/10.5751/ES-06592-190319 .
-
Moscovici, S. (1963). ‘Attitudes and opinions’. Annual Review of Psychology 14, pp. 231–260. https://doi.org/10.1146/annurev.ps.14.020163.001311 .
-
— (2000). ‘The phenomenon of social representations’. In: Social representations: explorations in social psychology. Ed. by G. Duveen. Cambridge, U.K.: Polity Press, pp. 18–77. URL: http://is.muni.cz/el/1423/podzim2013/SOC571E/um/S.Moscovici-SocialRepresentations.pdf .
-
National Academies of Sciences, Engineering, and Medicine (2017). Human genome editing: science, ethics, and governance. Washington, DC, U.S.A.: The National Academies Press. https://doi.org/10.17226/24623 .
-
Newman, D., Lau, J. H., Grieser, K. and Baldwin, T. (2010). ‘Automatic evaluation of topic coherence’. In: HLT ’10: Human Language Technologies: the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (Los Angeles, CA, U.S.A. 2nd–4th June 2010). Association for Computational Linguistics, pp. 100–108.
-
Newman, M. E. J. (2004). ‘Fast algorithm for detecting community structure in networks’. Physical Review E 69 (6), 066133. https://doi.org/10.1103/physreve.69.066133 .
-
Nielsen, K. M. (2003). ‘Transgenic organisms — time for conceptual diversification?’ Nature Biotechnology 21 (3), pp. 227–228. https://doi.org/10.1038/nbt0303-227 .
-
Nisbet, M. C. (2018). ‘The gene-editing conversation’. American Scientist 106 (1), pp. 15–19. https://doi.org/10.1511/2018.106.1.15 .
-
R Core Team (2020). R: a language and environment for statistical computing . Vienna, Austria: R Foundation for Statistical Computing. URL: https://www.R-project.org/ .
-
Rodríguez-Entrena, M. and Salazar-Ordóñez, M. (2013). ‘Influence of scientific-technical literacy on consumers’ behavioural intentions regarding new food’. Appetite 60, pp. 193–202. https://doi.org/10.1016/j.appet.2012.09.028 .
-
Rogers, E. M. (2010). Diffusion of innovations. New York, NY, U.S.A.: Simon & Schuster.
-
Savadori, L., Savio, S., Nicotra, E., Rumiati, R., Finucane, M. and Slovic, P. (2004). ‘Expert and public perception of risk from biotechnology’. Risk Analysis 24 (5), pp. 1289–1299. https://doi.org/10.1111/j.0272-4332.2004.00526.x .
-
Scheufele, D. A., Xenos, M. A., Howell, E. L., Rose, K. M., Brossard, D. and Hardy, B. W. (2017). ‘U.S. attitudes on human genome editing’. Science 357 (6351), pp. 553–554. https://doi.org/10.1126/science.aan3708 .
-
Seale, C., Charteris-Black, J., MacFarlane, A. and McPherson, A. (2010). ‘Interviews and Internet forums: a comparison of two sources of qualitative data’. Qualitative Health Research 20 (5), pp. 595–606. https://doi.org/10.1177/1049732309354094 .
-
Sherry-Brennan, F., Devine-Wright, H. and Devine-Wright, P. (2010). ‘Public understanding of hydrogen energy: a theoretical approach’. Energy Policy 38 (10), pp. 5311–5319. https://doi.org/10.1016/j.enpol.2009.03.037 .
-
Shew, A. M., Lanier Nalley, L., Snell, H. A., Nayga, R. M. and Dixon, B. L. (2018). ‘CRISPR versus GMOs: public acceptance and valuation’. Global Food Security 19, pp. 71–80. https://doi.org/10.1016/j.gfs.2018.10.005 .
-
Siegrist, M. (1999). ‘A causal model explaining the perception and acceptance of gene technology’. Journal of Applied Social Psychology 29 (10), pp. 2093–2106. https://doi.org/10.1111/j.1559-1816.1999.tb02297.x .
-
— (2000). ‘The influence of trust and perceptions of risks and benefits on the acceptance of gene technology’. Risk Analysis 20 (2), pp. 195–204. https://doi.org/10.1111/0272-4332.202020 .
-
Siegrist, M., Connor, M. and Keller, C. (2012). ‘Trust, confidence, procedural fairness, outcome fairness, moral conviction, and the acceptance of GM field experiments’. Risk Analysis 32 (8), pp. 1394–1403. https://doi.org/10.1111/j.1539-6924.2011.01739.x .
-
Sjöberg, L. (2008). ‘Genetically modified food in the eyes of the public and experts’. Risk Management 10 (3), pp. 168–193. https://doi.org/10.1057/rm.2008.2 .
-
Slovic, P. (1999). ‘Trust, emotion, sex, politics, and science: surveying the risk-assessment battlefield’. Risk Analysis 19 (4), pp. 689–701. https://doi.org/10.1111/j.1539-6924.1999.tb00439.x .
-
— (2016). ‘The perception of risk’. In: Scientists making a difference: one hundred eminent behavioral and brain scientists talk about their most important contributions. Ed. by R. J. Sternberg, S. T. Fiske and D. J. Foss. New York, NY, U.S.A.: Cambridge University Press, pp. 179–182. https://doi.org/10.1017/cbo9781316422250.040 .
-
Tanaka, Y. (2004). ‘Major psychological factors affecting acceptance of gene-recombination technology’. Risk Analysis 24 (6), pp. 1575–1583. https://doi.org/10.1111/j.0272-4332.2004.00551.x .
-
Veltri, G. A. (2013). ‘Microblogging and nanotweets: nanotechnology on Twitter’. Public Understanding of Science 22 (7), pp. 832–849. https://doi.org/10.1177/0963662512463510 .
-
Veltri, G. A. and Atanasova, D. (2017). ‘Climate change on Twitter: content, media ecology and information sharing behaviour’. Public Understanding of Science 26 (6), pp. 721–737. https://doi.org/10.1177/0963662515613702 .
-
Vishwanath, A. and Barnett, G. A., eds. (2011). The diffusion of innovations: a communication science perspective. New York, NY, U.S.A.: Peter Lang.
-
Wolter, F. and Puchta, H. (2017). ‘Knocking out consumer concerns and regulator’s rules: efficient use of CRISPR/Cas ribonucleoprotein complexes for genome editing in cereals’. Genome Biology 18, 43. https://doi.org/10.1186/s13059-017-1179-1 .
-
Wunderlich, S. and Gatto, K. A. (2015). ‘Consumer perception of genetically modified organisms and sources of information’. Advances in Nutrition 6 (6), pp. 842–851. https://doi.org/10.3945/an.115.008870 .
-
Wynne, B. (1980). ‘Technology, risk and participation: on the social treatment of uncertainty’. In: Society, technology and risk assessment. Ed. by J. Conrad. Cambridge, MA, U.S.A.: Academic Press.
-
Zywica, J. and Danowski, J. (2008). ‘The faces of facebookers: investigating social enhancement and social compensation hypotheses; predicting Facebook TM and offline popularity from sociability and self-esteem, and mapping the meanings of popularity with semantic networks’. Journal of Computer-Mediated Communication 14 (1), pp. 1–34. https://doi.org/10.1111/j.1083-6101.2008.01429.x .
Authors
Dr. Matthew Robbins
Department of Communication
University of California, Davis
One Shields Avenue
Davis, CA 95616
(406) 475-2239
E-mail:
mjrobbins@ucdavis.edu
.
Christopher Calabrese
Department of Communication
University of California, Davis
One Shields Avenue
Davis, CA 95616
(916) 521-9150
E-mail:
cjcalabrese@ucdavis.edu
.
Jieyu Ding Featherstone
Department of Communication
University of California, Davis
One Shields Avenue
Davis, CA 95616
(414) 368-7713
E-mail:
jding@ucdavis.edu
.
Dr. George A. Barnett
Department of Communication
University of California, Davis
One Shields Avenue
Davis, CA 95616
(530) 754-0976
E-mail:
gabarnett@ucdavis.edu
.