
Ten years have passed since the publication of an article by Savage and Burrows that enjoyed significant success and launched a still ongoing debate within social sciences. Entitled The Coming Crisis of Empirical Sociology , the article speculated that up to that moment certain research methods had ensured sociology a leading position in the field of theoretical research and reflection on social phenomena. However, according to the authors, such methods were running the risk of being overshadowed by the growing availability of digital data produced as a secondary effect by the countless transactions on the web (the so-called transactional data ), as well as the spreading of tools for collecting, processing and analysing such data in order to exploit their enormous marketing potential. As a strategy to address such issue, Savage and Burrows suggested involving transactional data, primarily those produced by social media, also in social research by adapting methods and techniques to the new digital reality [Savage and Burrows, 2007 ]. A few years later, Rogers put forward a similar proposal and suggested that digital methods should be developed to enrich and renew the apparatus of social research [Rogers, 2013 ]. Meanwhile, the invitation to start using such data not specifically produced for social research was reiterated by several other researchers.
Without entering the debate launched by Savage and Burrows, we can effectively take their argument as a good starting point to reflect on the relation between the Public Communication of Science and Technology (PCST) and social research, with particular reference to the recent developments in the latter that follow the direction envisaged by the two British sociologists. Indeed, if Savage and Burrows’s line of reasoning applies to sociology in general with regard to the massive data flow generated by social media, this is even more true for PCST research, which is a complex of activities that increasingly use social media and that concern a subject — science and technology — that is prominently featured in the flow of digital communication.
The first aspect worth focusing on is the supremacy attributed to the transactional data deriving from daily interactions on e-commerce and social media platforms. Unquestionably, it is a very important database for PCST, for example in the study of science and technology-related public controversies (from vaccines to climate change, from the so-called “web-democracy” to the more or less desirable effects of search engines). In fact, it should not be forgotten that it is virtually impossible to carry out any PCST activity without resorting to social media as well. However, it should not be overlooked that transactional data have two significant limitations. On the one hand, they are not always easily accessible for social research. On the other hand, they are short-lived, so to speak. With regard to the first aspect, such data are subject to strict privatisation policies that greatly reduce their availability for research, often with the excuse of protecting the privacy of producers/consumers (the so-called prosumers , according to a successful definition by Ritzer and Jurgenson [ 2010 ]). In relation to the second aspect, these data tend to remain crystallised in the present, both because social media and e-commerce platforms are quite recent creations, and because they are exposed to Simmelian fashion cycles (WhatsApp has partially replaced Facebook, and the same is happening with SnapChat, and then who remembers SecondLife?). Additionally, they tend to appeal to different types of users and thus reduce their representativity; moreover the habits of their users change over time thanks to naturalisation and collective reflection processes that modify them (today, for example, a growing awareness on data processing issues is redefining what goes through the web, as evidenced by the birth and expansion of the so-called “deep-web”). It should also be added that excessive adherence to the present can be a problem for social research, which must maintain a necessary distance from the phenomena it intends to analyse, even if “detachment” must be cleverly balanced with an equally necessary “involvement”, as suggested by Elias [ 2007 ] and recently highlighted by Frade [ 2016 ]. Finally, one should not fall into the trap of technological neutrality: the web is not a simple substrate on which contents and interactions travel, but it equally contributes to modelling both of them. Social media and e-commerce platforms participate in the processes that involve them, if nothing else because of the algorithms that make them work and that actively participate in the interactions they create [Gillespie, 2014 ].
So, the features that make transactional data attractive — especially their uninterrupted production and their genuineness, that is the fact of being generated during normal social interactions and not responding to stimuli conceived to answer questionnaires used for research purposes — come out at least partially weakened by a number of aspects that reduce their relevance to social research.
Anyway, while transactional data are undoubtedly interesting to social research in general and PCST in particular, another still unexplored opportunity has recently emerged to take up the suggestion by Savage and Burrows to renew sociology. The digitisation of traditional media, such as newspapers, opens up new scenarios of great importance not only for the study of the media coverage of science and technology, but also for dealing with issues such as the social representations of techno-science and its relation with public opinion.
Similarly to social media, newspapers contain “naturally” produced texts, i.e. not specifically conceived to answer a questionnaire or an interview, nor built within artificial contexts such as a focus group or an ethnographic observation, in which — as is known — subjects are well aware of being under observation. Digital newspapers present less barriers to their use as a database for social research. In addition, they provide a medium- or long-term perspective, as the archives of major newspapers, at least in Italy, allow for a retrospective analysis up to the early 1990s. 1
Of course, even in the case of newspapers there are a number of problems that are far from secondary, and that require a brief explanation.
Firstly, the correspondence between what can be observed by analysing newspapers — and in general the mass media — and the rest of social reality remains an open question. It should be considered, among other things, that the mass media cannot certainly be merely taken for transmission channels or simple tools for describing social phenomena, since they play an active role themselves in the creation of social dynamics. However, it is worth stressing that the same problem concerns the relationship between “on-line” and “off-line”, between what is happening and can be seen on the web and what is going on outside the web. Also in this case, we have to deal with a very intensive long-term debate, both when the subject is the so-called traditional media (for example, think of the problem concerning the effects of the media, which remains unsolved despite the large amount of theoretical reflections and empirical research projects in this field) and when it is the new media, including social media. 2
Secondly, differently from social media, newspaper contents do not come from ordinary citizens, but from journalists, and this could considerably harm the use of traditional media to understand social phenomena. However, while the selective and biased character of the media’s narrative remains out of the question, today’s dynamics should not trick us into believing that what happens on social media is a more direct and therefore more faithful representation of our world: in fact, even what prosumers write and do on social media is the result of interpretation processes stemming from a personal viewpoint.
Furthermore, there are good reasons to take the content of newspapers as an indicator of what is happening in the wider social context in which the media thrives, drawing on the cultural climate that it contributes to building, spreading, reproducing and transforming. For example, as appropriately argued by Scheufele, the communication frames of both traditional and new media contents derive from the general social context, which is at the same time influenced by the media [Scheufele, 1999 ]. Therefore, with all due caution, newspapers can rightfully be taken as proxies of public opinion: with controversial technical and scientific issues in particular, some surprising correspondence sometimes occurs [Neresini and Lorenzet, 2016 ].
1 The TIPS project as an example of computational social science applied to PCST
The TIPS project (Technoscientific Issues in the Public Sphere) finds its place within the framework outlined above. This analysis of the media discourse on science and technology was launched to monitor its evolution and to exploit the social life of the data produced by online newspapers (i.e. the texts of the articles) as proxies of public opinion. 3 Owing to the intrinsically multi-disciplinary character of the project, researchers from different sectors contribute to it: sociology, ICT, statistics, social psychology and linguistics are involved in an attempt to integrate knowledge, theoretical perspectives and research methods that belong to different fields of social sciences, with particular reference to science and technology studies (STS), content analysis, the social representations theory and computer science.
The inter-disciplinary strategy pursued by the research group that launched and has then developed the TIPS project can therefore be summarised as follows: using the potential deriving from the digitisation of newspapers to study the relation between techno-science and society, according to a logic similar to the one suggested by Savage and Burrows, yet trying to overcome certain limitations connected with the use of transactional data.
Keeping in mind that purpose, within the TIPS project a web-platform was set up to develop, experiment and implement automatic procedures for the acquisition, classification and analysis of the digital contents available on the web — mainly taken from news sources, but also from social media — with a view to monitoring the presence and the evolution of issues related to science and technologies. This platform collects and organises within an online database the documents produced by a number of sources, currently the eight most important newspapers in Italy (Il Corriere della Sera, La Repubblica, La Stampa, Il Sole24Ore, Avvenire, Il Giornale, Il Messaggero, Il Mattino), five news organisations in English (The NYTimes, The Guardian, The Mirror, The Telegraph, The Times of India), six in French (Figaro, Lacroix, Le Monde, Les Echos, Liberation, Parisien), as well as the 100 most relevant Italian blogs and approximately 100 Twitter accounts in Italian. 4
At the beginning of 2017, the TIPS platform database included over 1,300,000 articles published in Italian newspapers (the entire collection January 2010-onwards from Corriere della Sera, La Repubblica, La Stampa, and Il Sole24Ore; with the other four newspapers, the entire collection starts from 2013), as well as 750,000 articles in English (the entire collection from the five newspapers January 2014-onwards); over 700,000 articles in French (the entire collection from the six newspapers January 2014-onwards); a sample of 162,000 articles published in Il Corriere della Sera and La Repubblica over the 1992–2012 period; over 500,000 posts published on the blogs and a few thousands of tweets.
The considerable quantity of data already available, which is bound to grow, makes a manual analysis impossible. Consequently, the TIPS project envisages automatic processing and analysis techniques, implementing those already available with a few adaptations if required, or developing new ones if possible.
For this reason, aside from systematically collecting documents, the TIPS platform can automatically analyse their content by applying classifiers and indexes specially devised for such purpose. The following indexes are already available:
- salience = ratio between the number of articles classified as relevant for a specific subject and the total of articles published over the same period by the source;
- prominence = ratio between the number of articles classified as relevant for a specific subject published on the homepage and the total articles published on the homepage over the same period by the source;
- general framing = distribution of the relevant articles across the various sections of the news websites (for example, aside from the homepage, politics, domestic news, business, sports, culture, etc.);
- risk = presence in an article text of a set of words associated with the risk domain.
2 Following techno-science on newspapers
In order to present a few results of the TIPS platform, let us start from the salience trend for the articles classified as featuring relevant technical-scientific content over the 2010–2016 period. 5
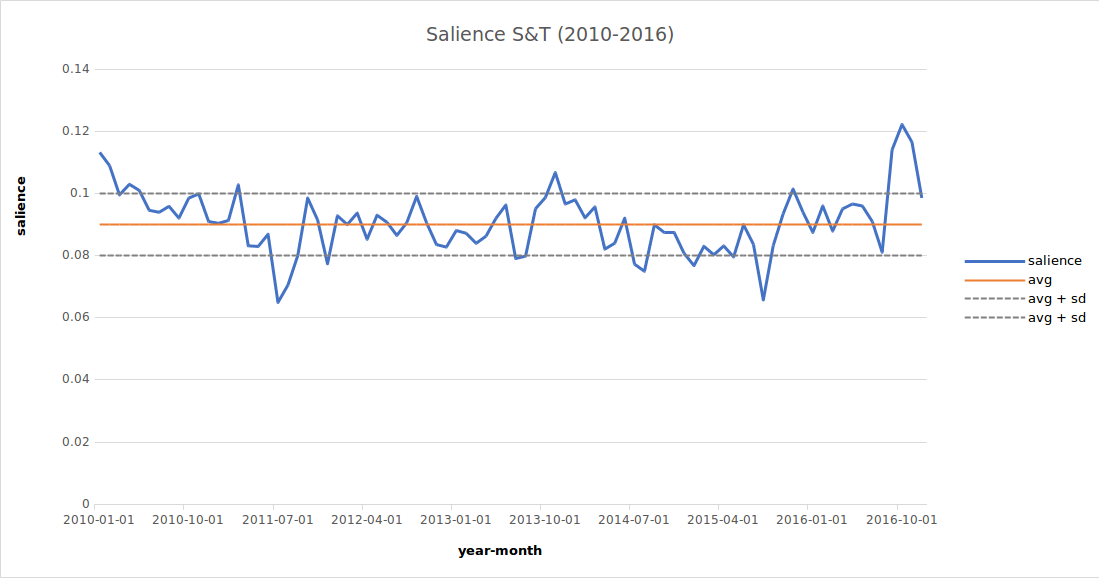
As it can be seen, the salience of techno-science in the media discourse shows a certain stability, even though the overall number of the articles published in the four newspapers monitored significantly increased over time. Techno-science therefore plays a well-established role in our social context, and it makes no sense to conceive and treat it as a world apart. Conversely, it is an integral part of our daily life, while scientific research and technological innovation appear to be social activities having a great relevance.
On the graph showing the salience trend (Figure 1 ), it is possible to observe an area comprised between the two dotted lines corresponding to a somewhat “natural” oscillation of salience. 6 By defining such a standard variability zone, it is possible to identify a few peaks, i.e. times in which techno-science affected the media discourse in a more evident way.
The reflection on certain methodological aspects concerning the longitudinal analysis of the coverage of techno-science by newspapers will be presented below. For now, it is worthwhile to briefly analyse the peaks identified above. 7 For example, the increase in salience reported in March 2011 was mainly due to the Fukushima nuclear accident and the presentation of the new iPad. On the other hand, in November 2013 it is more difficult to ascribe the peak to specific events. This clearly shows that the presence of techno-science in the newspapers mainly depend on several small pieces of news, adding up only a limited number of events having a significant impact. The latter included, among others, the return of the Italian astronaut Parmitano from the International Space Station, the controversy surrounding the Stamina case, the smartphone patent war between Samsung and Apple. Two years later, still in November, other two events captured the attention of newspapers: the UN climate change conference in Paris and the debate on the use of the Expo area in Milan as a venue for a scientific campus.
But how is techno-science perceived by the general public? By comparing the weight and the trend of the risk indicator in the articles concerning techno-science and in other articles, some interesting information in this regard can be drawn. Firstly, it can be noted that in the media discourse about techno-science the risk indicator tends to decrease over time. However, by comparing this trend with the one similarly identifiable in all the articles published over the same period, it becomes immediately evident that it is general, and therefore this trend relating to techno-science should not be interpreted as a sign of a public perception less inclined to evaluate it in terms of risk.
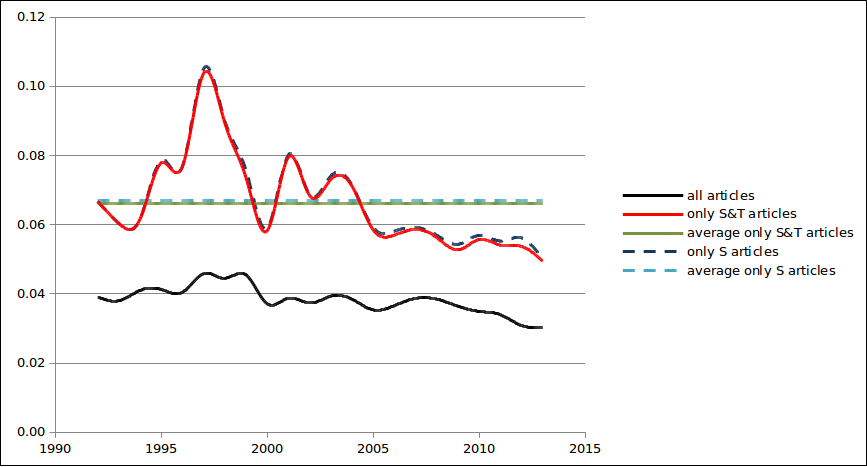
In addition, by making a distinction between techno-science-related articles and articles dealing with science in strict terms in the comparison of the risk indicator trend — in Figure 2 S&T and S respectively — it can be noted that the two curves substantially overlap. Consequently, whether it is about science or technology, the reference to the risk domain basically does not change. This raises serious doubts about the quite widespread belief that science and technology should be treated separately, at least in the public sphere.
3 Epistemological and methodological issues
Beyond the results, the experience gained over the years by working according to the TIPS project logic can yield a few methodological remarks. These are important in order to fully evaluate the potential, but also the limits of PCST research based on the use in a computational social science perspective of the enormous amount of textual data available today through the digitisation of traditional media.
We will proceed schematically, aiming to only provide an overview of the possible issues involved in this research perspective, rather than an in-depth discussion about each of them.
3.1 Building the object of analysis, selecting the corpus
It may sound obvious or trivial, but a decisive factor for a proper and efficient PCST research based on newspapers is the construction of the corpus. In this regard, there are at least two issues to consider: finding the articles and selecting them so as to obtain a corpus relevant to the research for which one intends to use it.
As concerns the retrieval, it should be considered that — although the digitisation of the media textual content has made it possible to overcome many constraints that complicated its use in the analogue version — the acquisition of the articles published in newspapers still requires a certain effort. Obviously, the main problem is the access to existing archives or, alternatively, the construction of specific archives, but the issue of formats should not be overlooked. For example, texts sent or stored as images have a format that makes the processing with automatic content analysis tools very complicated. The retrieval is then related to the issue of selection. The TIPS project experience shows that in order to have a correct view of the media discourse on techno-science, so much in general terms as it relates to specific issues, it is always necessary to perform a comparative analysis: articles dealing with techno-science versus articles dealing with others subjects, articles dealing with an issue relevant to techno-science (biotechnology, research policies, bioethics, etc.) versus all articles featuring over the same period relevant content for techno-science broadly speaking. Only a comparative view allows us to grasp the trend in the coverage of techno-science by newspapers. For example, the evident growth over time in the number of articles that concern techno-science should not be taken for an increase in their relevance on the media scene: on the contrary, the salience indicator shows that it was basically stable over time. 8 Similarly, only a comparison can establish whether certain features observed in a specific issue really distinguish it from the others.
But the problem of selection also touches the even more complicated question of the definition of the item to be studied. This appear to be easily solvable with relatively specific subjects: if one intends to study the media discourse on nanotechnology, one will only need to select all the articles containing the term “nanotechnology”. In fact, the reality is slightly different: often either the abbreviation “nano” and other terms as “nanoscience” are used as synonyms, or nanotechnology can be referred to using periphrases such as “the world of infinitely items” or “the research at atomic level”. If the issue is less simple than what it may seem with relatively specific subjects, one can easily infer it becomes extremely complex when the subject of the analysis has more blurred boundaries, as is the case with techno-science. What do we mean exactly by “techno-science”? Should science and technology be treated separately? And if so, where does the line of distinction fall? These are not merely philosophical or sociological questions: the answer to those question is the basis to the operational procedure to be used to select articles, and therefore to build the database (corpus) for our analysis. The solution adopted by TIPS, for instance, could be defined as a pragmatic approach based on assumptions deriving from STS: science is a social activity, therefore made by someone, within an organisation, through the use of certain instruments, structured in disciplinary fields with a specific nomenclature and additionally it is an activity that produces contents spread by journals or in specific occasions (congresses, conferences, etc.). If an article contains at least a couple of references to those — easily identifiable — pragmatic aspects of scientific research, then we can say we are dealing with a content relevant to our analysis of techno-science in the public sphere.
3.2 Granularity, periodisation and sampling biases
The second methodological aspect we can briefly discuss concerns the organisation of the time dimension of the analysis. As we initially claimed, the chance to reconstruct the evolution of the media discourse on techno-science over the medium or long term is one of the elements that support the choice of newspapers as a database instead of transactional data.
To use this opportunity at best, two only apparently minor aspects should be defined. The first concerns the so-called granularity, i.e. the time unit with which data are structured, analysed and displayed. Clearly, if the time frame considered is relatively short — say one year — the distribution of the contents presented by the articles can be divided into months, or into weeks, whereas when the time frame considered is longer — say a decade — the options available also include longer time units (years, semesters, four-month periods, etc.). However, the smallest time unit for newspapers is obviously a day. In this regard, apparently there is not an optimal selection parameter, if not practicality; however, it should not be forgotten that the granularity chosen greatly affects what can be observed and therefore inferred in the analysis. A different issue is periodisation. It is customary to resort to periodisations using time frames corresponding to granularity. This solution, although the easiest and most direct one, can be problematic, as it does not take into account a crucial feature of media communication. In the media — both traditional or new — the presence of certain contents can indeed be “spotted” — an article on nuclear energy today, another after a month, and so on — or take the form of “stories” related to more or less relevant events — the announcement of a new energy policy by the government, an accident at a nuclear plant, etc. — and therefore narratives having lifecycles with varying length and recurrence.
For this reason, a periodisation divided into fixed time units — a year, a month, a week, etc. — may artificially interrupt such cycles, giving a distorted image of the media discourse. On the basis of that, it would be wiser to devise a periodisation matching more the media communication dynamic. With TIPS, the solution adopted (see Figure 1 ) was to consider the oscillation around the average salience value as the standard oscillation zone, and consequently the values of salience outside such zone as “peaks” in the media discourse.
It should be noted that the dynamic characterising media communication, and which makes a fixed-period time division rather questionable, is also the reason why the construction of corpora using sampling procedures cannot be satisfactory, especially taking into account that almost in all cases the sampling unit corresponds to a day. Indeed, should the random selection fall on days in a coverage peak instead of a standard oscillation interval, the situation would change dramatically, resulting in an over- or under-representation of the media discourse on techno-science.
3.3 Validity
Finally, the third methodological aspect concerns a general issue for the research, i.e. validity. How can we be reasonably certain we are observing the circumstances we are interested in?
In the case of the public discourse on techno-science analysed through newspapers, how can we know that the articles selected for our corpus are indeed relevant to our subject of study? In part, this problem leads us back to the construction of the corpus as previously discussed. On the other hand, it also shows a pitfall lying in the research strategies based on large quantities of data, as with the TIPS project. Clearly, when working with hundreds of thousands of articles, the validity check cannot be performed manually. Consequently, the tests must be carried out on samples. Luckily enough, in this domain there is a long experience gained in IT research that deals with data retrieval, which we will not even discuss here, of course. But there is another point to highlight: no automatic processing technique is able to solve the issue of validity without being based on the researchers’ perception, which inevitably introduces a series of choices, assumptions and opacity in epistemological terms. However, no other modus operandi exists, and we should always be aware of such ineluctability, despite the apparent objectivity that can be easily attributed to automatic analysis instruments.
4 One final point: research purposes first of all!
The issue of validity is not trivial at all, also because it is closely connected with the risk of taking as an actual ‘black box’ the software currently available for the processing of large quantities of textual data, often applying algorithms of high complexity. Of course, social scientists could hardly become also competent statisticians and computer scientists, but that is not the point. The point is to pursue an informed and somewhat critical use of such instruments by knowing — at least in principle — the assumptions on which they are based and the procedures that make them work. This helps to choose the ones that are most useful for the research, bearing in mind their main limitations and correctly interpreting their outputs. 9
This could also prevent a sort of “data bulimia” due to the endless availability of data that are easily accessible and processed through software that can reduce their complexity, thus yielding significant results beyond the apparent chaos of the initial data. This form of “data bulimia”, which leads to increasingly larger quantities of data processed at an increasingly faster pace, hides the danger of overlooking the centrality of the purpose of the research, the need to go beyond the merely descriptive level and face new challenges in the field of knowledge that, albeit implying the risk of failure, may help us understand something more of the world we live in.
Translated by Massimo Caregnato
References
-
Elias, N. (2007). Involvement and Detachment. Dublin, Ireland: University College Dublin Press.
-
Frade, C. (2016). ‘Social Theory and the Politics of Big Data and Method’. Sociology 50 (5), pp. 863–877. https://doi.org/10.1177/0038038515614186 .
-
Gillespie, T. (2014). ‘The Relevance of Algorithms’. In: Media Technologies. Ed. by T. Gillespie, P. J. Boczkowski and K. A. Foot. Cambridge, MA, U.S.A.: The MIT Press, pp. 167–194. https://doi.org/10.7551/mitpress/9780262525374.003.0009 .
-
Hoffmann, L. (2013). ‘Looking back at big data’. Communications of the ACM 56 (4), pp. 21–23. https://doi.org/10.1145/2436256.2436263 .
-
Murthy, D. (2008). ‘Digital Ethnography: An Examination of the Use of New Technologies for Social Research’. Sociology 42 (5), pp. 837–855. https://doi.org/10.1177/0038038508094565 .
-
Neresini, F. and Lorenzet, A. (2016). ‘Can media monitoring be a proxy for public opinion about technoscientific controversies? The case of the Italian public debate on nuclear power’. Public Understanding of Science 25 (2), pp. 171–185. https://doi.org/10.1177/0963662514551506 .
-
Ritzer, G. and Jurgenson, N. (2010). ‘Production, Consumption, Prosumption: The nature of capitalism in the age of the digital ‘prosumer’’. Journal of Consumer Culture 10 (1), pp. 13–36. https://doi.org/10.1177/1469540509354673 .
-
Rogers, R. (2013). Digital methods. Cambridge, MA, U.S.A.: MIT Press.
-
Savage, M. and Burrows, R. (2007). ‘The Coming Crisis of Empirical Sociology’. Sociology 41 (5), pp. 885–899. https://doi.org/10.1177/0038038507080443 .
-
Scheufele, D. A. (1999). ‘Framing as a theory of media effects’. Journal of Communication 49 (1), pp. 103–122. https://doi.org/10.1111/j.1460-2466.1999.tb02784.x .
-
Vogt, C., Castelfranchi, Y., Righetti, S., Evangelista, R., Morales, A. P. and Gouveia, F. (2012). ‘Building a science news media barometer SAPO’. In: The culture of science. How the public relates to science across the globe. New York/London: Routledge, pp. 400–417.
-
Wouters, P., Beaulieu, A., Scharnhorst, A. and Wyatt, S., eds. (2013). Virtual Knowledge. Cambridge, MA, U.S.A.: The MIT Press. URL: https://mitpress.mit.edu/books/virtual-knowledge .
Author
Federico Neresini teaches Science, Technology and Society and Sociology of Innovation at the University of Padua (Italy). His research has been focused on biotechnology and nanotechnology; recently he also addressed to the relationship between big-data and scientific research activities, as well as the implications of big-data for the social sciences.He published several articles in international journals — such as Nature, Science, Public Understanding of Science, Science Communication, New Genetics and Society, Tecnoscienza — and some books. E-mail: federico.neresini@unipd.it .
Endnotes
1 In a few instances, e.g. La Stampa and Il Corriere della Sera — two of the main Italian newspapers in terms of longevity and circulation — online newspaper archives feature the full collection of the issues. However, in those cases, older pages do not have a format suitable for automatic analysis, and therefore laborious OCR (optical character recognition) conversions are required, often yielding results of too low a quality.
2 On the opportunity of using on-line materials as a database to study the off-line world see, inter alia, Wouters et al. [ 2013 ], Murthy [ 2008 ] and Rogers [ 2013 ].
3 The original idea of monitoring the science coverage in newspapers derives from the SAPO project [Vogt et al., 2012 ]. The TIPS project started out as an evolution of the SMM (Science in the Media Monitor) project, carried out by Observa under the scientific coordination of Federico Neresini.
4 The modular structure of the platform makes it possible to add new sources if necessary. For example, also El País (Spain) and Jornal de Notícias were recently included, while the addition of six further newspapers from Latin America is currently being evaluated. The selection of the newspapers is based on two criteria: circulation and representativity of the various editorial approaches existing in the landscape of the news organisations from each country.
5 The TIPS platform uses a series of automatic classifiers able to establish whether an article features contents relevant for a specific subject. The classifier used to select articles featuring a relevant technical and scientific content is based, for example, on an algorithm that gives each article a score according to the presence in the text of a number of keywords specifically weighed and combined; if the score is higher than a preset threshold, then the article is classified as “relevant” for techno-science. The platform provides for various classifiers to be used interchangeably so that, for example, it can select articles relevant also for other subjects, such as food safety, science, nanotechnology, synthetic biology. Further classifiers can be added based on research needs.
6 In operational terms, TIPS defines the standard oscillation zone as the one comprised between the values equal to average standard deviation (sd) and average sd.
8 For this reason, the TIPS platform collects and stores all the articles published in the monitored newspapers.
9 An interesting reflection in this regard was made by Hoffmann [ 2013 ], with reference to computational history.