
Like a small creek that meets a larger stream and eventually joins a raging river, astronomical data are ever growing and accelerating. New telescopes with improved collecting abilities and increasingly sophisticated instruments provide scientists with data that literally have never been seen before.
How astronomers capture and communicate their observations is an issue that stretches back centuries. For millennia, skywatchers recorded what they observed using hand drawings, conveying to the best of their abilities what they saw with the only “telescopes” they had at their disposal: their eyes. Even after Galileo and others invented the first telescopes in the early 17th century, hand-drawn sketches were still the only means to communicate the new and improved views they were afforded. This eye-to-hand recording system continued until photography was invented in the mid-1800s. For the first time, observations were captured permanently on photographic plates and film as an “anthology of images” [Sontag, 1977 ].
Progressing from hand-drawn sketches to photography represented a major advance in the collection of astronomical data, but it pales in comparison to advances made over recent decades in the form of dozens of new telescopes, both on the ground and in space [DeVorkin, 1993 ; Portree, 1998 ]. This new telescopic armada not only looks at the kind of light that humans can detect with their eyes, known as visible or optical light, but also at the full span of the electromagnetic spectrum ranging from radio waves to gamma rays, not visible to the naked eye [Arcand et al., 2013 ; Arcand and Watzke, 2015 ; Benson, 2009 ]. For the past 25 years, the amount of astronomical data has doubled every year [Stephens et al., 2015 ]. Astronomy could be called the original big data — both literally and figuratively.
As an illustration, consider humanity’s single natural satellite — the Moon. Scientific illustrations moved from a hand drawn moon recorded by Galileo in the early 1600s [Whitaker, 1978 ], to the first daguerreotype of our Moon created in Cambridge, Massachusetts with the Smithsonian Astrophysical Observatory’s 15” Great Refractor in 1847 [Unknown, 1887 ], to the advanced charge-coupled devices (CCD’s) on board NASA’s Lunar Reconnaissance Orbiter launched in 2009 ( https://doi.org/10.1007/s11214-010-9634-2 ). Thus, over 400 years, representations of the Moon have progressed from a hand-sketch of three times magnification to a photographic camera with a pixel scale of 0.5 meter per pixel that can image a 25 km region [Arcand et al., 2013 ; Rector, Arcand and Watzke, 2015 ].
Although this flood of astronomical data itself has the potential to alter our perceptions and understanding of cosmic objects, it is not the only force at play. One must consider the fact that many objects in space are themselves changing. Some change dramatically over the course of centuries, others over decades, still others from year-to-year [Rector, Arcand and Watzke, 2015 ]. Thus, for some objects in space, important differences can be observed during the span of a human lifetime, and those observations can be visualized across wavelength, time, and dimension.
As described in Arcand et al. [ 2013 ], processing astrophysical data requires the data processor to make a series of choices in the representation. From the data state (whether a 2D visual representation, a time lapse movie, a 3D map, or other plot), to the color choices, to the data selected to be left in or taken out, the range of technical choices in creating a visual representation of an astronomical object is large. Beyond the technical choices, there is the key aspect of the science story being told. Important decisions must be made that take into consideration the audience for whom the science is being communicated, and how that audience will be accessing that information [Rector, Arcand and Watzke, 2015 ].
Previous research has shown that effective science communication about objects in space for the lay public needs to be different from that which is provided for those with more expertise in astronomy. For the lay public, comprehension of the underlying science is affected by the type of explanation provided, rationales for colors used, and an indication of the scale of the object [Smith et al., 2011 ]. The use of metaphor and/or leading questions in explanations aids comprehension for those who do not have much expertise, while those with more expertise prefer shorter, more technical explanations [Smith et al., 2017 ]. Similarly, comprehension and aesthetic appreciation is affected by the size and quality of an image when compared across various types of mobile devices [Smith et al., 2014 ]. Another consideration is that with the popularity of photo-editing images, belief in the veracity of the object has been shown to be somewhat less for males than females [Smith et al., 2015b ]. Notwithstanding these differences between experts and non-experts, it is heartening to note that the lay public has shown a desire to understand the science in the same manner of those who are more expert. However, they work from an initial reaction to an image of “WOW!” to questions about the science. Experts have been shown to start with the science and then move toward the “WOW” [Smith et al., 2011 ]. Combining the findings from that body of research with the range of types of visualization of images available currently formed the basis for this study.
0.1 Data framework: supernova remnant Cassiopeia A
Consider the debris fields left behind after a giant star has exploded. These objects, known as supernova remnants, contain the cosmic nutrients necessary to grow life as we know it [Sagan, 1980 ]. Cassiopeia A (Cas A for short) is one such supernova remnant. The Cas A supernova remnant is one of the most famous objects in the sky; it has been observed numerous times by many satellites and observatories, creating a large data set with which to work. Two dimensional images of Cas A from telescopes such as NASA’s Chandra X-ray Observatory show a forward shock, dense knots, complex filamentary structures, and a jet of material protruding out of the shell [Tucker, 2017 ]. Beyond morphology, astronomers have used Chandra to map the heavy elements that were ejected in the supernova blast. Separate iron, silicon, and calcium images, created from each element’s characteristic emission lines, gave important clues as to the nature of the explosion and the state of the star prior to explosion. The jet in the northeastern corner was seen to be made predominantly of silicon ions [Hwang et al., 2004 ; Hwang, Holt and Petre, 2000 ].
Working with Cas A, different color selections then can be chosen based various features, such as topography (e.g., https://www.nasa.gov/mission_pages/ msl/multimedia/pia16800.html ), chemical makeup [DePasquale, Arcand and Edmonds, 2015 ], energy levels [ ‘What determines the aesthetic appeal of astronomical images?’ ] or other possibilities. In addition, there are often differences between color maps typically used for expert vs non-expert audiences [Moreland, 2016 ].
In 2004, Chandra observed Cas A for over a million seconds, yielding an extremely detailed image of the supernova remnant. In the years since then, astronomers have continued to observe Cas A with Chandra for over another million seconds. This has made possible time-lapse movies of the various data sets to show the remnant changing over time [Patnaude and Fesen, 2006 ].
Because Cas A is the result of an explosion, the stellar debris is expanding radially outwards from the explosion center. Using simple geometry and the Doppler effect, researchers can create 3-D models out of X-ray, infrared, and optical data. The insight into the structure of Cas A gained from such 3-D visualizations is important for astronomers who build models of supernova explosions. For example, researchers must consider that the outer layers of the star eject spherically, while the inner layers eject in a more disk-like way with high-velocity jets in multiple directions [DeLaney et al., 2010 ; Milisavljevic and Fesen, 2013 ].
With the use of timelapse movies and 3D modelling, video, additional factors specific to videos need to be considered, such as video length and type [Ruedlinger, 2012 ].
The question arises as to how these various types of images are perceived by viewers with a range of expertise in astronomy. Therefore, our objective for this research was to examine the effect of different types of visual presentations of a deep space object, in this case, Cassiopeia A (Cas A). The research question was: how do different presentations of an object in deep space affect understanding, engagement, and aesthetic appreciation?
1 Method
To explore the research question, an online survey was created using SurveyMonkey. A description of that survey, and details regarding the participants, procedure, and analyses follow. It should be noted that responses were required for all items with the exception of the two open-ended questions and the item asking for gender.
1.1 Participants
Participants were a convenience sample of respondents to an online survey. Using an open-ended format for gender, there were (44.7%) respondents who self-reported as male, as female; and, who chose not to respond. The remaining responses comprised who identified as gender fluid ( ) and each self-identified as queer and bisexual ( ).
Age was roughly evenly distributed among those under age 45, with somewhat higher representation from those aged 45 and older. The self-reported responses to age were for 18–24 years, for 25–34 years, for 35–44 years, for 45–54 years, for 55–64 years, and for 65 and above.
The participants were well-educated, with reporting having earned an advanced degree (masters, law, medical, or doctorate), with an undergraduate degree, with some university, and with some high school or a high school/secondary diploma.
A variety of occupations were reported. The most frequently reported were computer/technical ( ), retired ( ), student ( ), education/librarian ( ), Science-related ( ), medical/health ( ), arts/entertainment/sports ( ), and astrophysicist/astronomy-related ( ).
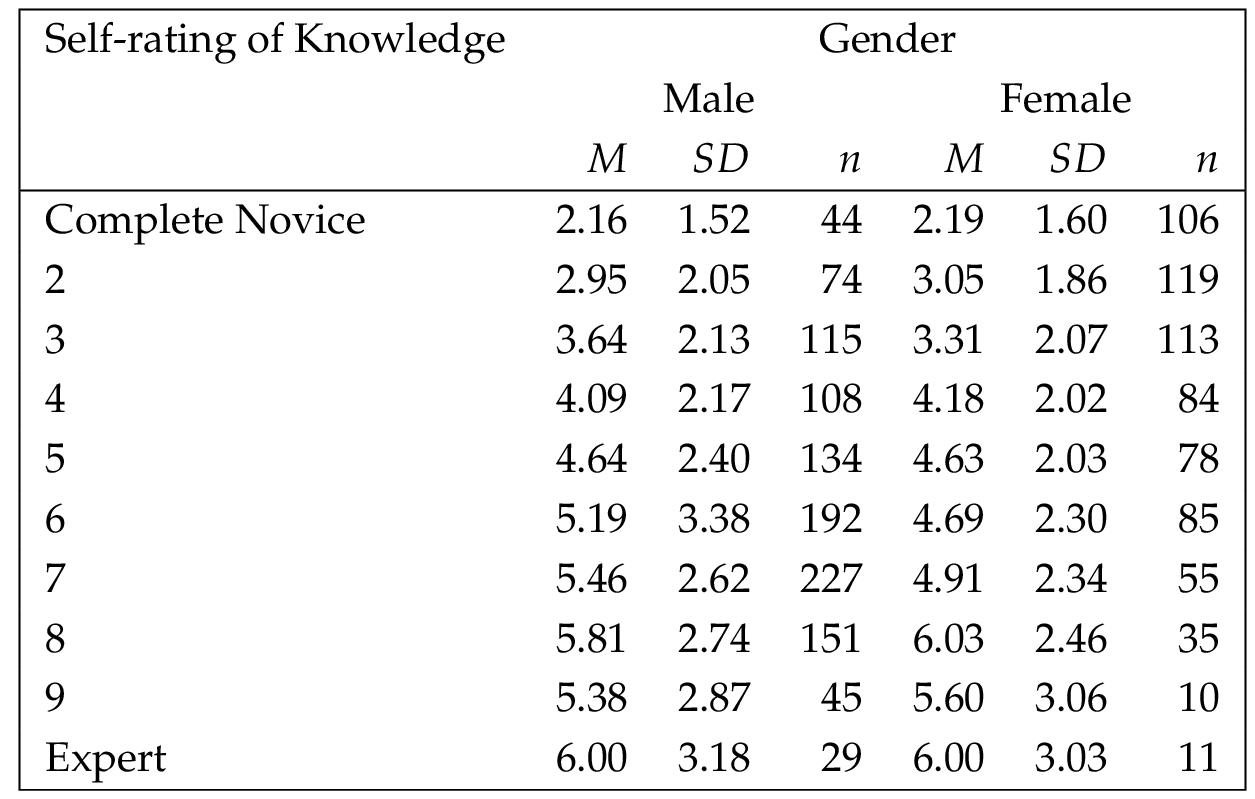
In terms of level of expertise, the participants provided a self-evaluation of their knowledge of astronomy, using a scale from 1 (complete novice) to 10 (expert), the mean response was 4.97 ( ). The distribution of responses was fairly even for ratings from 1 through 8, (ranging from 9.0% to 14.9%); however, fewer participants rated themselves as 9 or 10 (3.0% and 2.8% respectively). To facilitate analyses, these were collapsed into three categories, each approximating one-third of the sample (Low = 1–3, 32.4%; Medium = 4–6, 36.7%; and High = 7–10, 30.9%).
Participants also provided information regarding their background in astronomy. They could check multiple responses from a list. A total of participants reported that they read about astronomy online; reported that it was a hobby; had taken one or more university courses in astronomy; reported having studied astronomy in secondary/high school; participated in an amateur astronomy organization; reported being professional astronomers; held a degree in astronomy but were not working in a related field; and, reported having no background.
As this was an online survey, we were interested in the type of computer platform used. Two-thirds of the participants used a desktop computer ( ) or a laptop ( ). The remaining participants reported having used a smartphone ( ), followed by a tablet ( ), and a mini-tablet ( ).
1.2 Materials
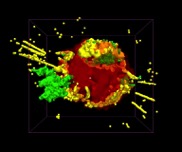
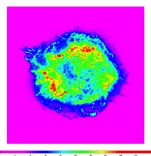
An online survey created for this study used 11 versions of the supernova remnant Cassiopeia A (Cas A) as stimuli, comprising six images and five videos ranging from 3 s to approximately 1 min. Figure 1 shows the six images used, static views of the five videos, and brief labels to identify the images and videos. The survey items are described in the Procedure.
1.3 Procedure
Upon receiving notification that this research was exempt by the Smithsonian Institution Human Subjects Institutional Review Board, participation was sought from a range of websites and listservs chosen to represent those with an interest in astronomy, museum professionals in the field of art and aesthetics, and the lay public. Websites included the Chandra X-ray Observatory (chandra.si.edu); the Astronomy Picture of the Day (apod.nasa.gov); the Aesthetics and Astronomy website (astroart.cfa.harvard.edu); social media sites such as Facebook, Twitter, and Instagram; and, the American Psychology Association Division 10 and the International Association of Empirical Aesthetics listservs.
The first page of the survey provided general information about the study including how to obtain the results, advised that the survey was open to those 18 years of age or older, that data would be reported in aggregate, and that the survey would take approximately 10 m to complete. Each respondent then checked a box to indicate that completion of the survey signified agreement to the age condition and consent to participate.
Next, each participant was randomly assigned to either one of the images or one of the videos. That is, each participant viewed only one of the stimuli. No time limit was placed on viewing the images; videos could be replayed. After viewing their randomly assigned image or video, the participants were asked, “In viewing this image or video, what most comes to mind?” Possible responses were solicited from astrophysicists, image developers, and psychologists. Based on those suggestions, a list of 10 responses were provided: a meteor, an asteroid, a comet, an exploded star, a star being born, something seen under a microscope, a distant planet, a distant sun, a black hole, and a brain image. They were then given the same list of options and asked, “What else do you think of when viewing this image or video?”
The next part of the survey asked participants to use a scale of 1 (not at all) to 10 (a great deal) to rate three items: how much they wanted to learn more about the image or video, how much appeal the image or video had, and how well the participant understood about the image or video.
At that point, participants were advised that “What you viewed was an image or video of Cassiopeia A in one of several formats used by astrophysicists;” and, they were shown this label:
Cassiopeia A is a young supernova remnant in our Milky Way Galaxy, believed to be the leftovers of a massive star that exploded over 300 years ago. The material ejected during the supernova smashed into the surrounding gas and dust at about 16 million kilometers per hour. This collision superheated the debris field to millions of degrees, causing it to glow brightly in X-rays as observed by NASA’s Chandra X-ray Observatory.
The next two items used the same 1 (not at all) to 10 (a great deal) scale, asking how much the explanation increased understanding and how well the image or video represented the nature of the object depicted.
These items were followed by an open-ended item that asked, “If an astronomer were with you, what additional question(s) would you ask about the image or video that you viewed?”
The survey concluded with the demographic items described in the section on participants, and a final open-ended item that provided the opportunity for participants to add any additional comments about the survey.
The quantitative data were analyzed using SPSS Version 24. With the qualitative data from the two open-ended items, two researchers used Strauss and Corbin’s [ 1998 ] grounded theory approach to independently develop a series of categories for the responses. They then compared and agreed upon a final set of categories for each of the open-ended items, independently rated responses for each image or video separately, and checked for inter-rater reliability. There were fewer than 6% discrepancies, which were resolved through discussion.
2 Results
Given the small number of participants who had completed the survey on a tablet or mini-tablet, a series of analyses of variance (ANOVAs) were used to determine whether there were differences on responses to items, by type of computer. Computer platform was used as the independent variable, with the items gender, age group, self-rating of knowledge of astronomy, initial appeal, wanting to learn more, initial understanding, increased understanding, and how much the image represents the object used as dependent variables. Results were non-significant for these analyses, suggesting that type of computer platform would not affect results for other analyses for this sample. Also, given the size of the sample, was used as the level of significance for all analyses.
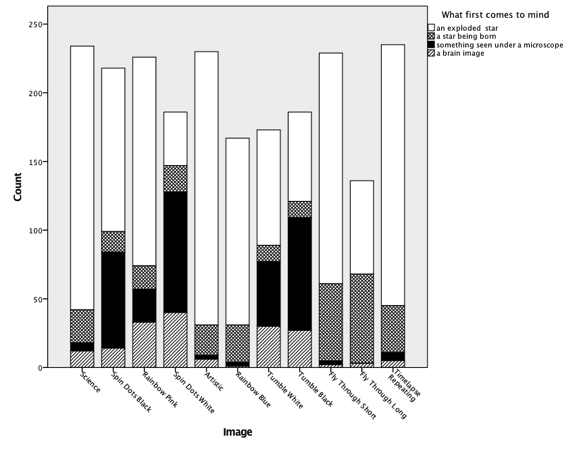
To begin, responses to the item “In viewing this image or video, what most comes to mind?” were examined using chi-square. The result was significant, , , with over half of the sample having chosen the correct option, an exploded star ( ; 56.0%). There were fewer 100 responses each for the options: a meteor, an asteroid, a comet, a distant sun, a distant planet, and a black hole. As such, those six options were dropped from the analysis and the chi-square was re-calculated using the remaining four options: an exploded star, a star being born, something seen under a microscope, and a brain image. The resulting chi-square statistic was , . The response counts and percentages, in order, were an exploded star ( ; 63.6%), something seen under a microscope ( ; 15.0%), a star being born, ( ; 13.6%), and a brain image ( ; 7.8%). Figure 2 shows these results by image. From that figure, it can be seen that although the most prevalent choice was “an exploded star,” the different depictions of Cas A yielded different reactions from the participants. Results from the item, “What else do you think of when viewing this image or video?” did not add useful information, as responses from those who first selected an exploded star were most likely to select a star being born ( ; 40.2%). This was a logical second choice; therefore, additional analyses were not conducted for that item.
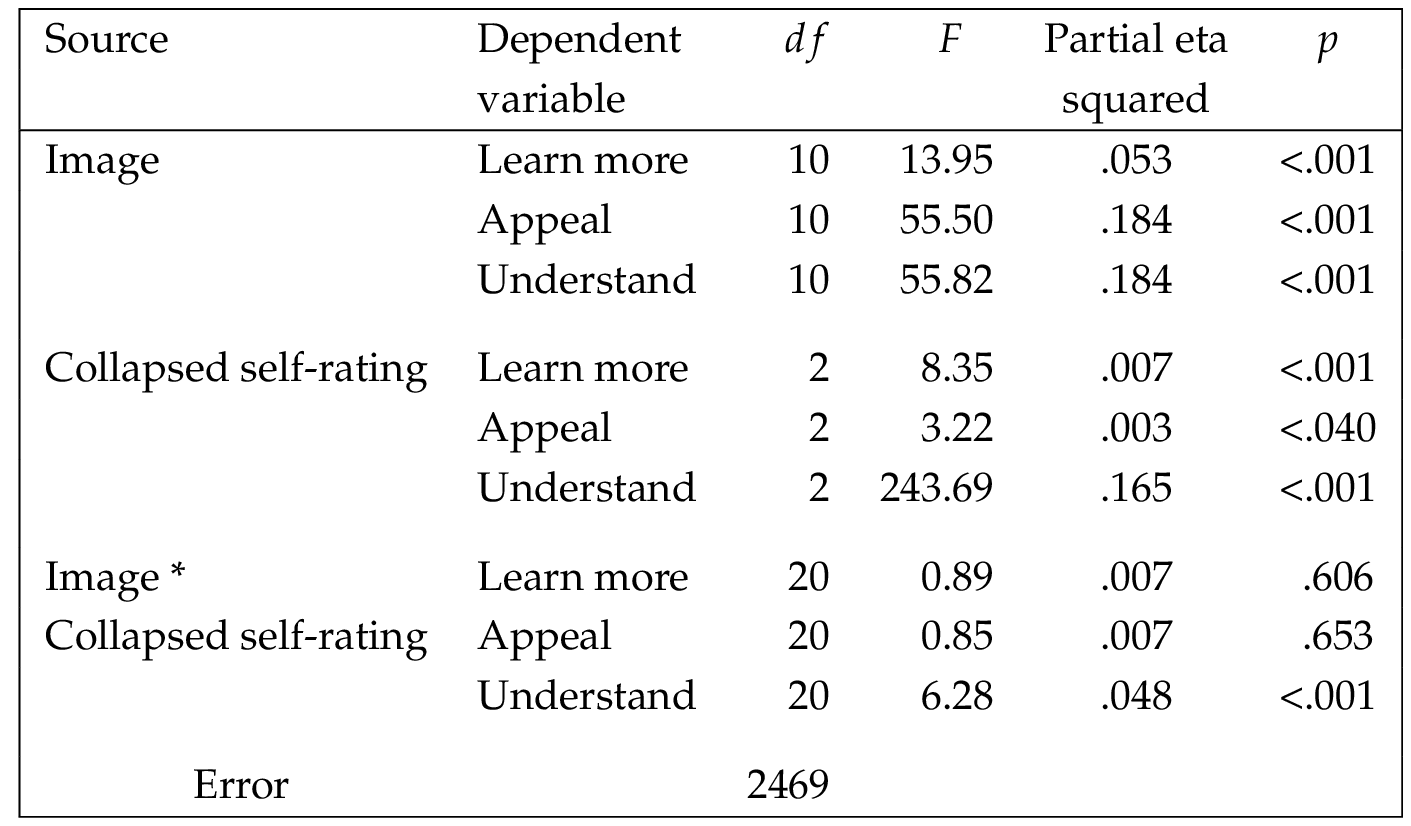
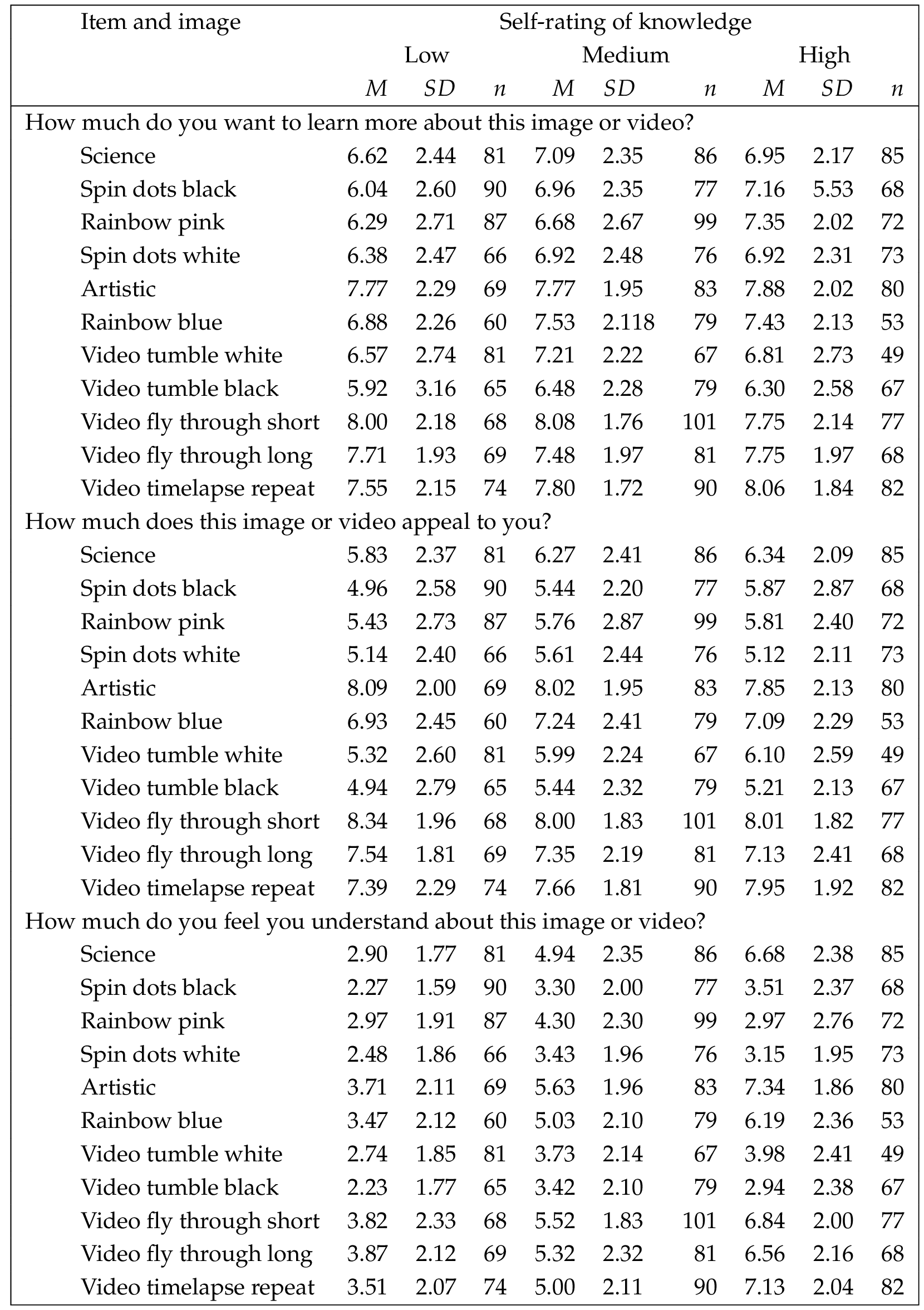
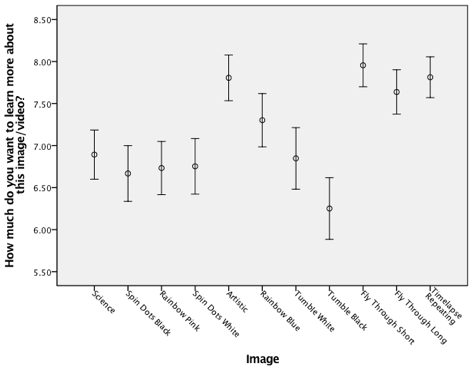
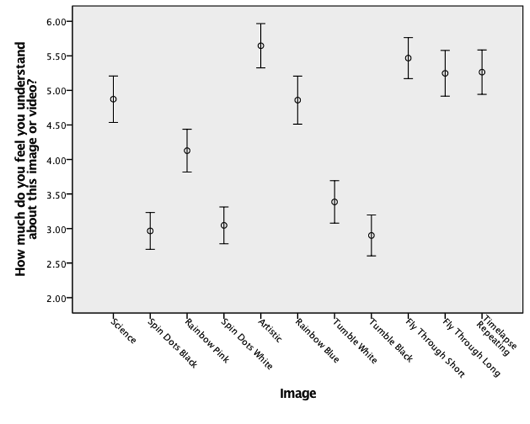
Next, a multivariate analysis of variance (MANOVA) and univariate ANOVAs were used to investigate the research question, how do different presentations of an object in deep space affect understanding, engagement, and aesthetic appreciation? The first analysis was a MANOVA, with the images and the collapsed self-rating of knowledge of astronomy item used as the independent variables, and the initial three items given before the presentation of the label (wanting to learn more, initial appeal, and initial understanding) used as the dependent variables. The results were significant. For the interaction of image with self-rating, (60, 7361.01) , ; Wilk’s , partial . For the main effect for image, , ; Wilk’s , partial and for the main effect for self-rating, , ; Wilk’s , partial . The univariate results for the interaction were significant only for initial understanding. For the main effects, both image and self-rating were significant for all three items. The univariate results are shown in Table 1 ; Table 2 shows the descriptive statistics for the univariate analyses. Figure 3 provides graphs of these data with error bars. It can be seen that for the six still images, for the items wanting to learn more and initial appeal, the artistic image yielded the highest mean rating, followed by the rainbow blue image. For understanding, the artistic, science, and rainbow blue images received the highest mean ratings (in that order). For the five videos, across all items, the fly through short yielded the highest mean rating, with the timelapse and the fly through long videos also rating highly.
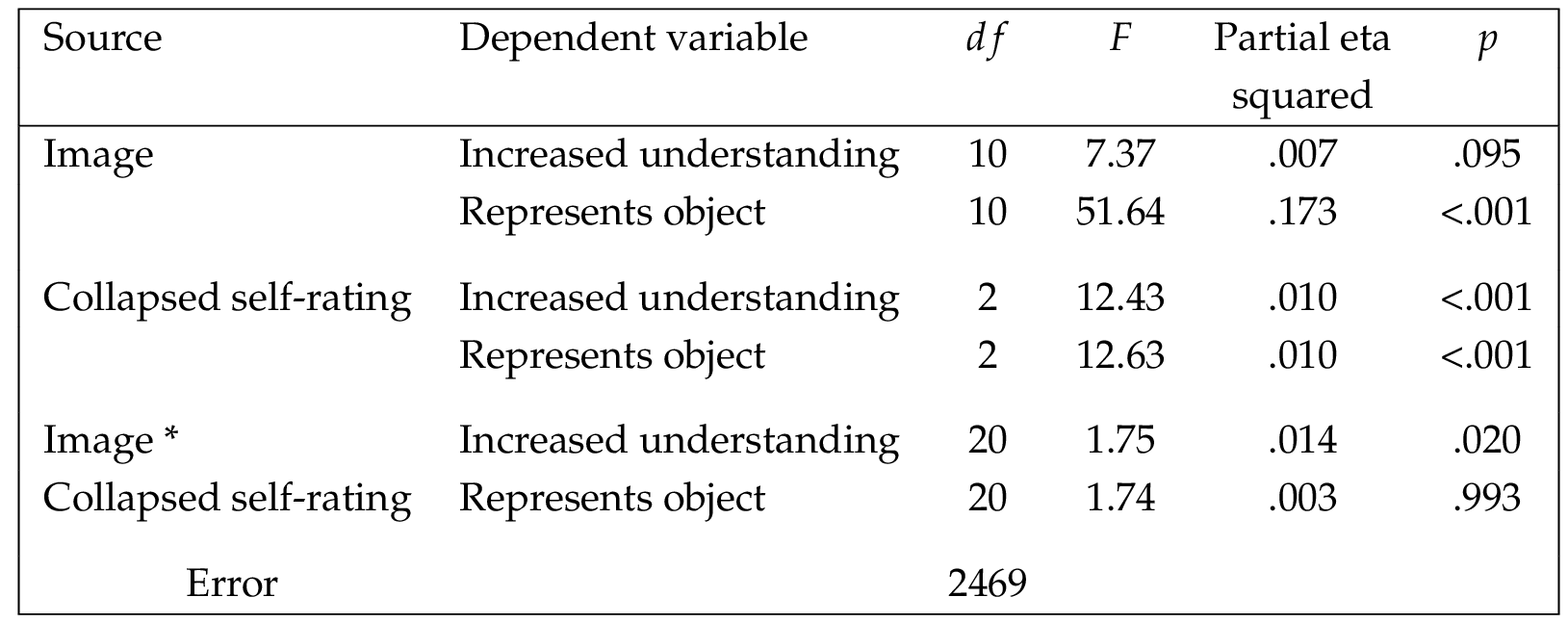
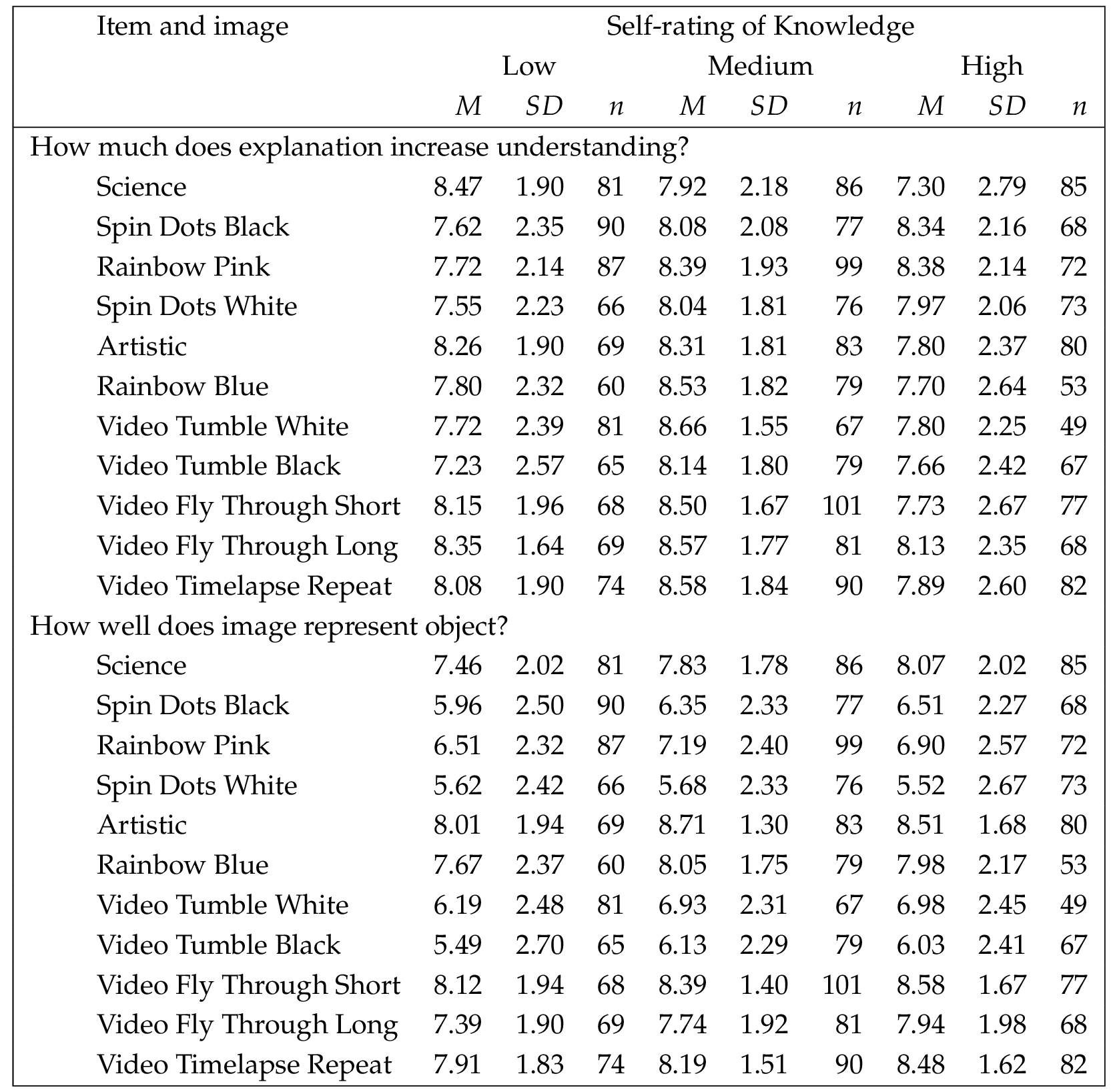
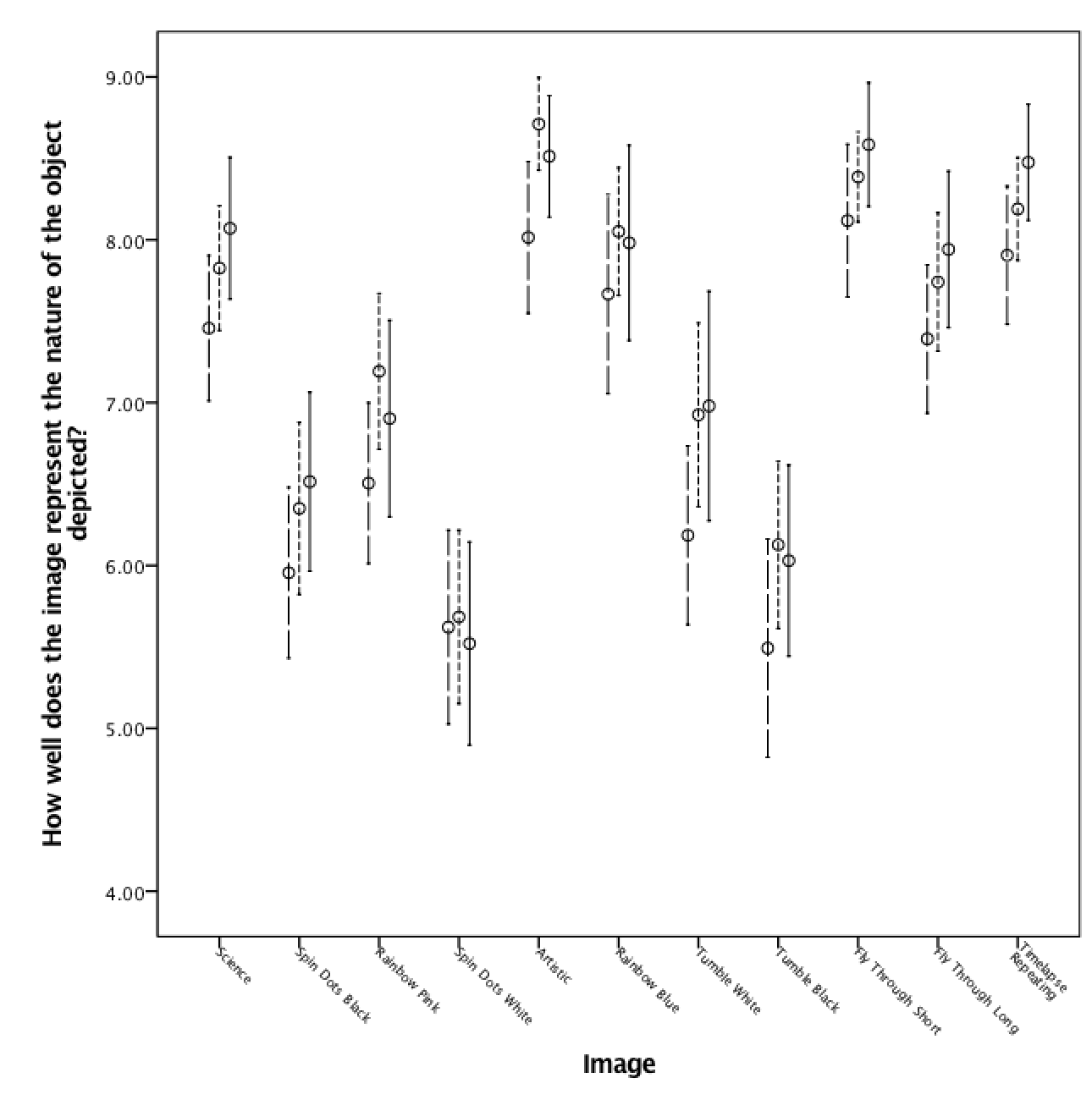
The next two analyses used ANOVAs to examine the responses to the two items that followed the presentation of the label. These items asked how much the explanation increased understanding and how well the image or video represented the nature of the object depicted. They were used as the dependent variables, with the images and the collapsed self-rating of knowledge of astronomy item used as the independent variables. Results for the ANOVAs are shown in Table 3 ; descriptive statistics are shown in Table 4 . Again using a significance level of , it can be seen that there were no interaction effects. There was one main effect for representing the object, for image or video; for self-rating of knowledge, both main effects were significant. Figure 4 presents graphs of these data with error bars. The graph for how much the explanation increased understanding suggests that, with the exception of the science image, those who self-rated their knowledge in the middle range reported receiving the most benefit from the explanation. For the science image, average ratings were highest for the low self-rating group, and decreased across the mid- and high-self-rating groups. Overall, though, given that ratings were done on a scale of 1 (not at all) to 10 (a great deal), it can be seen that the explanation was helpful across all of the images and videos, for all levels of expertise. For the graph for how well the image or video represented the nature of the object, large differences by object are observed. For the images, artistic, rainbow blue, and science received the highest average ratings; for the videos, fly through short, timelapse, and fly through long showed the highest average ratings. Within each object, however, the differences by self-rating of knowledge are fairly consistent, typically following a pattern of low-medium-high.
Next, age and gender were examined against the five independent items of interest. Age group was correlated with the items wanting to learn more, initial appeal, and initial understanding, how much the explanation increased understanding, and how well the image or video represented the nature of the object depicted. No significant results were obtained, suggesting that age did not affect ratings for those items. For gender, independent samples -tests were used, with gender ( male, female) as the independent variable and the five items as dependent variables. Only one of the items was significant: initial understanding, , . The means and standard deviations indicated that on average, males initially reported higher levels of initial understanding as compared to females ( , male; , female). However, upon further examination using an independent samples -test, with gender as the independent variable and self-rating of knowledge as the dependent variable, , , with , male and , female. This suggested that the finding for initial understanding was related to self-reported knowledge. To examine that, an analysis of covariance was run, with initial understanding as the dependent variable, gender as the independent variable, and self-rating of knowledge as the covariate. There was no interaction effect or main effect for gender; only the main effect for self-rating of knowledge was significant (see Tables 5 . The means and standard deviations are shown in Table 6 . This supports the finding that the gender differences on initial understanding are attributable to self-reported knowledge.
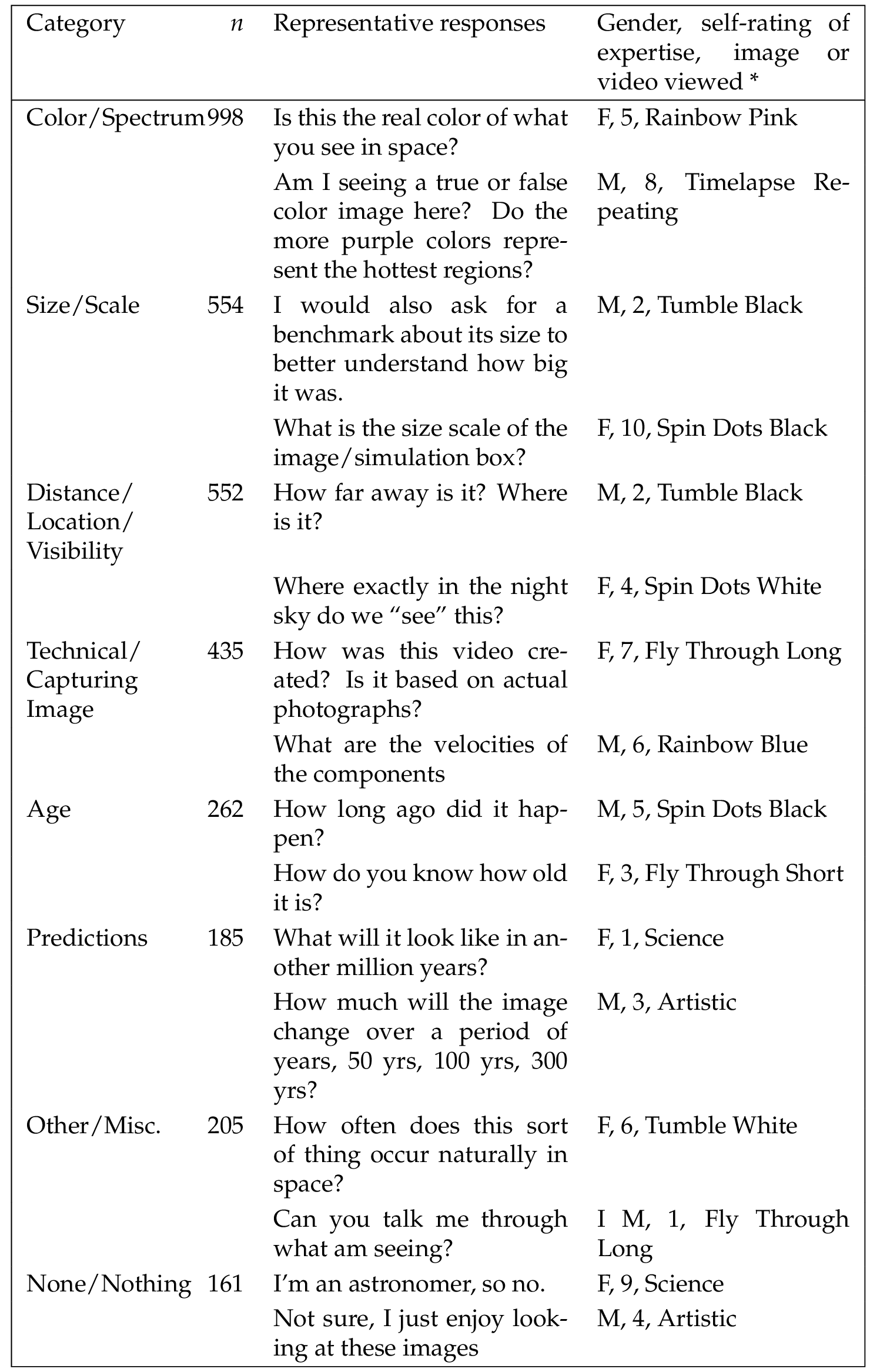
The final analyses concerned the two open-ended items. The first item asked, “If an astronomer were with you, what additional question(s) would you ask about the image or video that you viewed?” There was a total of 3,352 responses, which the raters grouped into eight categories: Age, Color/Spectrum, Distance/Location/Visibility, Predictions, Size/Scale, Technical/Capturing Image, Other/Miscellaneous, and None/Nothing. It should be noted that the number of responses does not equal the sample size, as some responses comprised multiple questions. Although the data were analyzed by image/video, responses to the categories were similar across the images/videos. Therefore, the data are shown in aggregate on Table 7 , with the total number of responses to each category, along with representative responses for each category. It can be seen that questions about the colors used were most prevalent, followed by requests for benchmarks for size, questions about the location of the object and whether it’s visible from Earth, and questions concerning how the image was captured.
The second open-ended item asked, “Is there anything more you’d like to tell us about this survey?” For this item, there was a total of 617 responses, with an additional indicating “no,” and the remainder leaving the item blank. The raters groups the responses into six categories: Thanks/Interesting/Enjoyable, Critiques/Suggestions, Aesthetics, Color, Use of Results, and Other/Miscellaneous. Responses were again similar across images/videos. Results are shown in aggregate on Table 8 , with the total numbers of responses to each category, along with representative responses for each category. The majority of the responses were messages of thanks for the work being done, and the desire to have the results put to use, in particular for the general public. Nearly all of the critiques or suggestions centered on not having been able to view the image while responding to the items in the second part of the survey regarding how much the explanation increased understanding and how well the image or video represented the nature of the object depicted, or not having wanted to have to choose a second response in response to the item “What else do you think of when viewing this image or video?”
3 Discussion
This study set out to explore how different presentations of an object in deep space affect understanding, engagement, and aesthetic appreciation. The main finding concerns the dramatic differences obtained for the images. Images that look familiar — that look like what the public thinks objects from space should look like — were rated on average as more appealing, easier to understand, and as promoting future learning. However, combining that with the finding that explanation, across all levels of self-knowledge of astronomy, benefited all participants, suggests that it is not necessary only to show recognizable images to the public. Rather, there is scope for the use of alternative types of images, provided they are accompanied by explanations. This is especially true when the images or videos begin to deviate from the familiar, for example when they start to look more like brain images than objects from space. In addition, the qualitative comments indicated that explanations would be more helpful if they described information about the colors used, and provided information about the size, scale, and location of the object. It is also noted that the results yielded no significant differences across computer platforms or age groups. In terms of gender differences, although males reported higher levels of initial understanding on average than did females, males also reported higher levels for self-reported knowledge.
The results from this study lend support to previous findings [e.g. Arcand et al., 2013 ; Smith et al., 2011 ] that those with less expertise want more information regarding the colors used and whether those colors have been processed, as well as information about the scale, size, and location of the object. However, unlike Smith et al.’s [ 2014 ] findings that the type of computer platform mattered, this study suggests that the type of device did not have a significant effect on the responses. Perhaps in the absence of viewing the object comparatively on a larger or smaller device, the participants engaged in what Locher, Smith and Smith [ 1999 ] termed facsimile accommodation , and adjusted to the image as viewed regardless of the platform. With facsimile accommodation, the viewer understands that what is being viewed is not an actual object. This does not limit aesthetic or cognitive reactions; rather, those reactions tend to be similar to what might be experienced if the viewer were encountering the actual object.
In addition, comprehension of the underlying science for space images and appreciation of those images has been shown to be increased with the addition of informative labels [Smith et al., 2015a ]. In a recent study, Smith et al. [ 2017 ] demonstrated that when information for space images included metaphors and relevance to everyday life, viewers with less expertise made personal connections that increased their appreciation of the images and their desire to learn more. It is acknowledged that different audiences may resonate to different explanations; therefore, in terms of the current study, it might be useful to provide options for viewers to access additional explanations that include information such as relevance to life, or that expand on the science or on the use of the colors in a given image.
Even with random assignment to conditions, any research has limitations; this study is no exception. The greatest limitation for this study is that only one image, Cassiopeia A, was used. Also, although there were extensive efforts to secure participants from the general public, the data represent a convenience sample with some level of interest in astronomy and/or aesthetics. As such, application of the findings should not be generalized beyond the sample and procedures used. The findings suggest, however, that different representations of images can and even should be used, provided they are accompanied with appropriate explanations of the image itself and the science underlying what is being viewed.
A study is currently being planned that would expand the design from this research in terms of numbers and types of images, and varieties of explanations. Types of images will include presentations online, in-person, and with 3D prints, each paired with various types of explanatory formats, including static explanations, interactive narratives, videos, and podcasts. The suggestion to have the images available for viewing throughout the study has been incorporated into the design, as well.
In an age when imaging technology has become familiar to the public, it may be time to introduce atypical depictions of images from space alongside their more familiar counterparts, in an effort to attract and educate the public about these objects, and their effects on us and the Universe.
A Tables

* NOTE: M = Male, F = Female; Self-rating of expertise = 1 (complete novice) to 10 (expert).

* NOTE: M = Male, F = Female; Self-rating of Expertise = 1 (complete novice) to 10 (expert)
B Figures

(a)
Image
1:
Science.
|
(b)
Image
2:
Spin
Dots
Black.
|
(c)
Image
3:
Rainbow
Pink.
|
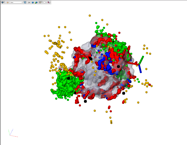
(d)
Image
4:
Spin
Dots
White.
|

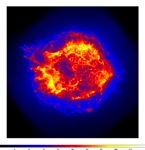
(e)
Image
5:
Artistic.
|
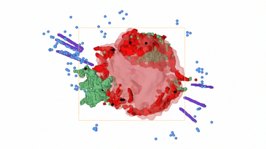
(f)
Image
6:
Rainbow
Blue.
|
(g)
Video
1:
3D
Tumble
White
(29s).
|

(h)
Video
2:
3D
Tumble
Black
(3s).
|

(i)
Video
3:
3D
Fly
Through
Short
(10s).
|

(j)
Video
4:
3D
Fly
Through
Long
(51S).
|

(k)
Video
5:
Timelapse
Repeating
(35s).
|
Video 2: 3D Tumble Black, http://chandra.si.edu/photo/2013/casa/animations.html .
Video 3: 3D Fly Through Short, http://chandra.si.edu/photo/2009/casa2/animations.html .
Video 4: 3D Fly Through Long, http://chandra.si.edu/photo/2009/casa2/animations.html .
Video 5: Timelapse Repeating,
http://chandra.si.edu/photo/2009/casa/animations.html
.
Continued on the next page
Continued from the next page
Key: Vertical lines represent grouped self-ratings with low, medium, and high groups from left to
right.
References
-
Arcand, K. and Watzke, M. (2015). Light: The visible spectrum & beyond. New York, NY, U.S.A.: Black Dog & Leventhal.
-
Arcand, K. K., Watzke, M., Rector, T., Levay, Z. G., DePasquale, J. and Smarr, O. (2013). ‘Processing Color in Astronomical Imagery’. Studies in Media and Communication 1 (2). https://doi.org/10.11114/smc.v1i2.198 . arXiv: 1308.5237 .
-
Benson, M. (2009). Far out: A space-time chronicle. New York, NY, U.S.A.: Abrams.
-
Christensen, L., Hainaut, O. and Pierce-Price, D. ‘What determines the aesthetic appeal of astronomical images?’ CAP Journal 14 (01), pp. 20–27. URL: https://www.capjournal.org/issues/14/14_20.pdf .
-
DeLaney, T., Rudnick, L., Stage, M. D., Smith, J. D., Isensee, K., Rho, J., Allen, G. E., Gomez, H., Kozasa, T., Reach, W. T., Davis, J. E. and Houck, J. C. (2010). ‘The three-dimensional structure of Cassiopeia A’. The Astrophysical Journal 725 (2), pp. 2038–2058. https://doi.org/10.1088/0004-637x/725/2/2038 .
-
DePasquale, J., Arcand, K. and Edmonds, P. (2015). ‘High Energy Vision: Processing X-rays’. Studies in Media and Communication 3 (2). https://doi.org/10.11114/smc.v3i2.913 .
-
DeVorkin, D. H. (1993). Science with a vengeance: How the military created the US space sciences after World War II. Corrected edition. Springer Verlag.
-
Hwang, U., Holt, S. S. and Petre, R. (2000). ‘Mapping the X-Ray–emitting Ejecta in Cassiopeia A with Chandra’. The Astrophysical Journal 537 (2), pp. L119–L122. https://doi.org/10.1086/312776 .
-
Hwang, U., Laming, J. M., Badenes, C., Berendse, F., Blondin, J., Cioffi, D., DeLaney, T., Dewey, D., Fesen, R., Flanagan, K. A., Fryer, C. L., Ghavamian, P., Hughes, J. P., Morse, J. A., Plucinsky, P. P., Petre, R., Pohl, M., Rudnick, L., Sankrit, R., Slane, P. O., Smith, R. K., Vink, J. and Warren, J. S. (2004). ‘A Million SecondChandraView of Cassiopeia A’. The Astrophysical Journal 615 (2), pp. L117–L120. https://doi.org/10.1086/426186 .
-
Locher, P., Smith, L. and Smith, J. (1999). ‘Original Paintings versus Slide and Computer Reproductions: A Comparison of Viewer Responses’. Empirical Studies of the Arts 17 (2), pp. 121–129. https://doi.org/10.2190/r1wn-taf2-376d-efuh .
-
Milisavljevic, D. and Fesen, R. A. (2013). ‘A detailed kinematic map of Cassiopeia A’s optical main shell and outer high-velocity ejecta’. The Astrophysical Journal 772 (2), p. 134. https://doi.org/10.1088/0004-637x/772/2/134 .
-
Moreland, K. (2016). ‘Why We Use Bad Color Maps and What You Can Do About It’. Electronic Imaging 2016 (16), pp. 1–6. https://doi.org/10.2352/issn.2470-1173.2016.16.hvei-133 .
-
Patnaude, D. J. and Fesen, R. A. (2006). ‘Small-Scale X-Ray Variability in the Cassiopeia A Supernova Remnant’. The Astronomical Journal 133 (1), pp. 147–153. https://doi.org/10.1086/509571 .
-
Portree, D. S. F. (1998). Monographs in aerospace history: NASA’s origins and the dawn of the space age. Washington, D.C., U.S.A.: NASA Headquarters History Division, Office of Policy and Plans.
-
Rector, T., Arcand, K. and Watzke, M. (2015). Coloring the Universe: An insider’s look at the making of space images. Fairbanks, AK, U.S.A.: University of Alaska.
-
Ruedlinger, B. (7th May 2012). ‘Does video length matter?’ Wistia . URL: https://wistia.com/blog/does-length-matter-it-does-for-video-2k12-edition .
-
Sagan, C. (1980). Cosmos. New York, NY, U.S.A.: Random House.
-
Smith, L. F., Smith, J. K., Arcand, K. K., Smith, R. K., Bookbinder, J. and Keach, K. (2011). ‘Aesthetics and Astronomy: Studying the Public’s Perception and Understanding of Imagery From Space’. Science Communication 33 (2), pp. 201–238. https://doi.org/10.1177/1075547010379579 . arXiv: 1009.0772 .
-
Smith, L. F., Arcand, K. K., Smith, J. K., Smith, R. K., Bookbinder, J. and Watzke, M. (2014). ‘Examining perceptions of astronomy images across mobile platforms’. JCOM 13 (02), A01. arXiv: 1403.5802 . URL: http://jcom.sissa.it/archive/13/02/JCOM_1302_2014_A01 .
-
Smith, L. F., Smith, J. K., Arcand, K. K., Smith, R. K. and Bookbinder, J. A. (2015a). ‘Aesthetics and Astronomy: How Museum Labels Affect the Understanding and Appreciation of Deep-Space Images’. Curator: The Museum Journal 58 (3), pp. 282–297. https://doi.org/10.1111/cura.12114 .
-
Smith, L. F., Arcand, K. K., Smith, J. K., Smith, R. K. and Bookbinder, J. (2015b). ‘Is That Real? Understanding Astronomical Images’. Journal of Media and Communication Studies 7 (5), pp. 88–100. https://doi.org/10.5897/jmcs2015.0446 .
-
Smith, L. F., Arcand, K. K., Smith, B. K., Smith, R. K., Bookbinder, J. and Smith, J. K. (2017). ‘Black holes and vacuum cleaners: Using metaphor, relevance, and inquiry in labels for space images.’ Psychology of Aesthetics, Creativity, and the Arts 11 (3), pp. 359–374. https://doi.org/10.1037/aca0000130 . arXiv: 1703.02927 .
-
Sontag, S. (1977). On photography. New York, U.S.A.: Farrar, Straus and Giroux.
-
Stephens, Z. D., Lee, S. Y., Faghri, F., Campbell, R. H., Zhai, C., Efron, M. J., Iyer, R., Schatz, M. C., Sinha, S. and Robinson, G. E. (2015). ‘Big Data: Astronomical or Genomical?’ PLOS Biology 13 (7), e1002195. https://doi.org/10.1371/journal.pbio.1002195 .
-
Strauss, A. and Corbin, J. M. (1998). Basics of qualitative analysis: Grounded theory procedures and techniques. 2nd ed. Thousand Oaks, CA, U.S.A.: Sage.
-
Tucker, W. (2017). Chandra’s cosmos. Washington, D.C., U.S.A.: Smithsonian Books.
-
Unknown (15th October 1887). ‘Harvard Observatory and the Henry Draper memorial’. Scientific American . URL: http://www.rarenewspapers.com/view/588268 .
-
Whitaker, E. A. (1978). ‘Gallileo’s drawings and writings’. Journal for the History of Astronomy 9, pp. 155–169.
Authors
Professor of Education Lisa F. Smith, Ed.D., University of Otago, New Zealand, conducts research on the psychology of aesthetics and the communication of science related to deep space imagery. She serves on the editorial boards of several peer-review journals, co-founded the American Psychological Association journal, Psychology of Aesthetics, Creativity, and the Arts, and is a Fellow of APA and of the International Association of Empirical Aesthetics. She has received two lifetime career awards for her research from IAEA and APA. E-mail: professor.lisa.smith@gmail.com .
Kimberly Kowal Arcand is the Visualization Lead for NASA’s Chandra X-ray Observatory, which has its headquarters at the Smithsonian Astrophysical Observatory in Cambridge, Massachusetts. She is a leading expert in the perception and comprehension of science data visualization, has led projects to create some of the first data-based 3D astronomical prints, and is active in the creation, distribution, and evaluation of large-scale science and technology communications projects for open access. E-mail: kkowal@cfa.harvard.edu .
Randall K. Smith, Senior Astrophysicist at the Smithsonian Astrophysical Observatory, is PI of the Arcus X-ray Grating Spectroscopy Mission and US representative to the European Space Agency’s Athena X-ray Satellite. Both roles involve regular presentation of science results to the public both in oral and written form, leading to his interest in science communications. E-mail: rsmith@cfa.harvard.edu .
Jay Bookbinder is the Director of Programs and Projects NASA’s Ames Research Center. He is a Co-Investigator on several NASA instruments including Solar Probe Plus mission’s SWEAP instrument suite, the IRIS SMEX telescope, the SDO/AIA instrument, and the Hinode/X-Ray Telescope. E-mail: jay.bookbinder@nasa.gov .
Jeffrey K. Smith is Professor of Education and Associate Dean for University Research Performance at the University of Otago in New Zealand. Previously, he was Professor at Rutgers University and also served as Head of the Office of Research and Evaluation at The Metropolitan Museum of Art. He has written or edited eight books and over 100 articles, chapters, and reviews on the psychology of aesthetics, educational assessment, and science communication. He has received two lifetime career research awards. E-mail: jeffreyksmith@gmail.com .